参考资料:
前置知识
print函数
print 函数的输出内容:数字、字符串、含有运算符的表达式
print 函数输出的地方:显示器、文件
print 函数输出的形式:换行与不换行
注释
单行注释:# 注释内容
多行注释:
- ‘’’ 注释内容 ‘’’
- “””注释内容”””
- 使用jupetr需要在后面加代码才能识别为多行注释
编码格式声明注释:
#coding:gbk —> 文件以gbk模式存储
#coding:utf-8 —> 文件以utf-8存储
python3 默认格式为utf-8
# 数字
print(1.2)
# 字符串
print('nihao')
# 含有运算符的表达式
# 3和1 为运算数, +-*/=等等为运算符。运算数+运算符的式子称为表达式
print(3+1)
1.2
nihao
4
# 输出到文件当中
# open('文件路径',‘选择那种方式打开文件’)
# a+ 表示在该路径下,有文件就以读写的方式打开文件并在文件后面继续追加内容,没文件就创建文件
fp=open('/Users/xieshaolin/workpalce/python/nihao.txt','a+')
print("nihao",file=fp)
fp.close()
print('ni')
print('hao')
# 用“,”进行分隔在一行进行输出, 默认两个字符串用 空格 隔开
print('ni','hao')
# 指定分割符 : sep
print('ni','hao',sep="*")
# 如果两个字符串直接不需要空格,可以指定 sep=""
print('ni','hao',sep="")
# print函数默认end=\n(换行符),end=','表示以','结尾 end=‘ ’ 表示以空格结尾
print('bu',end=' ')
print('hao',end=' ')
ni
hao
ni hao
ni*hao
nihao
bu hao
转义字符
\n —> 换行符
\t —> 制表符
\\—> 反斜杠
\'—> 单引号
不重要,遇到查一下就好
格式化输出
# %占位符 格式化输出
year = 2024
month = 2
date = 2
day = '⼀'
weather = '晴'
temperature = 20.5
# 今天是 2024 年 02 ⽉ 02 ⽇,星期 ⼀ ,今天的天⽓是 晴,温度是20.50
print('今天是 %d 年 %02d ⽉ %02d ⽇,星期 %s ,今天的天⽓是 %s,温度是%.2f' % (year, month, date,day, weather, temperature))
语法格式:
print("格式化字符串" % 变量1)print("格式化字符串" % (变量1, 变量2...))
% 被称为 格式化操作符,专⻔⽤于处理字符串中的格式
| 格式化字符 | 含义 |
|---|---|
%s |
字符串 |
%d |
有符号⼗进制整数,%06d 表⽰输出的整数显⽰位数,不⾜的地⽅使⽤ 0 补全 |
%f |
浮点数,%.2f 表⽰⼩数点后只显⽰两位 |
%% |
输出 % |
python 中的保留字与标识符(不重要,用多了就知道了)
保留字:如break,continue等(用多了就知道了)
标识符:严格区分大小写,不能以数字开头,字母数字和下划线
变量与数据类型
变量的定义与使用
变量由三个部分组成
如 name = '玛丽亚'
标识:上面的name,表示对象所存储的内存地址,id(obj)可以获取
类型:表示对象的数据类型,上面‘’表示该对象为字符串类型,type(obj)可以获取
值:表示对象所存储的具体数据,print(obj)可以获取
上面的 = 为赋值运算
name = '玛丽亚' 含义: 把一个字符串类型,值为玛丽亚的一个数据,赋值给name(内存地址)所代表的内存村空间
多次赋值后,变量名会指向一个新的空间
name = '玛丽亚'
print('值=',name,';name的内存地址=',id(name),';name的类型=',type(name))
name = '玛丽亚'
print('值=',name,';name的内存地址=',id(name),';name的类型=',type(name))
name = '玛丽亚'
print('值=',name,';name的内存地址=',id(name),';name的类型=',type(name))
# 以上三次赋值,内存地址都变了,表示3次赋值指向了不同的内存空间
值= 玛丽亚 ;name的内存地址= 4348995024 ;name的类型= <class 'str'>
值= 玛丽亚 ;name的内存地址= 4367296144 ;name的类型= <class 'str'>
值= 玛丽亚 ;name的内存地址= 4367295280 ;name的类型= <class 'str'>
数据类型
常用的数据类型
- 整数类型 –> int –> 100
- 浮点数类型 –> float –> 3.1415926
- 布尔类型 –> bool –> true/false
- 字符串类型–> str –> ‘人生苦短‘
# 整数类型的进制问题
print('默认十进制=',16)
print('0b开头表示二进制=',0b10000)
print('0o开头表示八进制',0o20)
print('0x开头表示十六进制',0x1)
# print默认输出的是十进制,所以print内部做出了转换,把其他进制都转换成了十进制
默认十进制= 16
0b开头表示二进制= 16
0o开头表示八进制 16
0x开头表示十六进制 1
# 浮点数存储不精确
print('1.1+2.2=%s'%(1.1+2.2))
# 浮点数之间的计算需要使用:decimal
from decimal import Decimal
print('1.1+2.2=',(Decimal('1.1')+Decimal('2.2')))
# 并不是所有的浮点数相加都不准确,这和二进制的底层相关
print('1.1+1.2=%s'%(1.1+1.2))
1.1+2.2=3.3000000000000003
1.1+2.2= 3.3
1.1+1.2=2.3
# 布尔值和整数可以相互转换
# True = 1 False = 0 注意首字母大写
print(True+1,False+1)
2 1
# 字符串又被称为不可变大夫序列
str1='使用单引号表示'
str2="使用双引号表示"
str3="""使用三引号,
可以换行"""
str4='''使用三引号,
可以换行'''
print(str1,type(str1))
print(str2,type(str2))
print(str3,type(str3))
print(str4,type(str4))
使用单引号表示 <class 'str'>
使用双引号表示 <class 'str'>
使用三引号,
可以换行 <class 'str'>
使用三引号,
可以换行 <class 'str'>
字符串的处理
字符串的运算
str1="ni"
str2="hao"
# 字符串加法:字符串拼接
str3=str1+str2
print(str3) # nihao
# 字符串乘法:重复字符串
str4=str3*3
print(str4) # nihaonihaonihao
字符串索引
# 创建字符串
s = 'hello,world'
# 索引计数从 0 开始。
print(s[0]) # h
print(s[4]) # o
# -1 反着数:也就是从world的字母d(-1),数到hello的字母h()
print(s[-1]) # d
print(s[-11]) # d h
字符串切片
切片的语法:变量名[起始索引:结束索引+1:步数]
# 切片 变量名[起始索引:结束索引+1:步数]
# 步数默认为1,可省略不写
# 起始索引默认为0,可省略不写
# 结束索引默认为-1,可省略不写
print(s[0:4]) # 包头不包尾 hell
print(s[6:9]) # wor
s2 = '123456789'
print(s2[0:9:2]) # 13579
print(s2[::3]) # 147
# 字符串反转
print(s2[-1:-10:-1]) # 987654321
# 如果倒着数:
# 起始索引默认为-1,可省略不写。而对应的结束位置也可以省略
print(s2[::-1]) # 987654321
数据类型转换
| 函数名 | 函数值 |
|---|---|
int(x, [基数] ) |
将数字或字符串转换为整数,如果x为浮点数,则自动截断小数部分 |
float(x) |
将x转换成浮点型 |
bool(x) |
转换成bool类型 的True或 False |
str(x) |
将x转换成字符串,适合人阅读 |
print('------------------int float bool --> str----------------------')
a = 9
b = 9.8
c = True
d = False
print(a,type(a),'===>',str(a),type(str(a)))
print(b,type(b),'===>',str(b),type(str(b)))
print(c,type(c),'===>',str(c),type(str(c)))
print(d,type(d),'===>',str(d),type(str(d)))
print('------------------str float bool --> int----------------------')
a1='9'
a2='9.8'
a3='nihao'
b1=10.7
c1=True
c2=False
# 只能把整数的字符窜转换为整数,小数或者文字的字符串都会报错
print(a1,type(a1),'===>',int(a1),type(int(a1)))
#print(a2,type(a2),'===>',int(a2),type(int(a2)))
#print(a3,type(a3),'===>',str(a3),type(str(a3)))
# 直接截取整数部分
print(b1,type(b1),'===>',int(b1),type(int(b1)))
# True=1 False=0
print(c1,type(c1),'===>',int(c1),type(int(c1)))
print(c2,type(c2),'===>',int(c2),type(int(c2)))
print('------------------str int bool --> float----------------------')
x='9'
y='9.8'
z='nihao'
u=9
v=True
w=False
#整数和小数可以转,字符不能
print(x,type(x),'===>',float(x),type(float(x)))
print(y,type(y),'===>',float(y),type(float(y)))
#print(z,type(z),'===>',int(z),type(int(z)))
print(u,type(u),'===>',float(u),type(float(u)))
print(v,type(v),'===>',float(v),type(float(v)))
print(w,type(w),'===>',float(w),type(float(w)))
------------------int float bool --> str----------------------
9 <class 'int'> ===> 9 <class 'str'>
9.8 <class 'float'> ===> 9.8 <class 'str'>
True <class 'bool'> ===> True <class 'str'>
False <class 'bool'> ===> False <class 'str'>
------------------str float bool --> int----------------------
9 <class 'str'> ===> 9 <class 'int'>
10.7 <class 'float'> ===> 10 <class 'int'>
True <class 'bool'> ===> 1 <class 'int'>
False <class 'bool'> ===> 0 <class 'int'>
------------------str int bool --> float----------------------
9 <class 'str'> ===> 9.0 <class 'float'>
9.8 <class 'str'> ===> 9.8 <class 'float'>
9 <class 'int'> ===> 9.0 <class 'float'>
True <class 'bool'> ===> 1.0 <class 'float'>
False <class 'bool'> ===> 0.0 <class 'float'>
小整数的地址问题
Python中的小整数,通常指的是**-5至256**之间的整数。
当你在Python中创建一个整数对象时,Python会根据该整数的值动态地为其分配内存空间。对于小整数,Python会使用一种称为“小整数缓存”的机制来优化内存使用。这个缓存池中的整数对象会被重复利用,而不是为每个新创建的小整数分配新的内存空间。这样可以减少内存分配和释放的开销,提高程序的性能。
如果你需要跟踪Python对象的内存地址,可以使用Python提供的内置函数id()来获取对象的唯一标识符,这个标识符通常可以用来近似地表示对象的内存地址。但是请注意,这个标识符并不是真正的内存地址,而是由Python解释器生成的一个唯一标识符,用于区分不同的对象实例。
xieshaolin@MacBook-Pro ~ % python3
Python 3.8.2 (default, Jun 8 2021, 11:59:35)
[Clang 12.0.5 (clang-1205.0.22.11)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> a=1
>>> id(a)
4511501040
>>> b=1
>>> id(b)
4511501040
>>> b=2
>>> id(b)
4511501072
>>> c=300
>>> id(c)
4514118896
>>> d=300
>>> id(d)
4514118832
>>> exit()
运算符
input 函数
present=input(str)
str –> 打印在控制台的语句
present –> str类型,是我们输入的语句
age=input("请输入你的年龄:")
print(age)
# age 的任性是一个str
print(type(age))
# 可以转换成int类型
age=int(age)
print(type(age))
请输入你的年龄:66
66
<class 'str'>
<class 'int'>
python中的运算符
- 算术运算符
- ‘+’ 加法运算符
- ‘-’ 减法运算符
- ‘*’ 乘法运算符
- ‘/’ 除法运算符
- ‘//’ 整除运算符
- ‘%’ 取余运算
- ‘**’ 幂运算符
- 赋值运算符
- =赋值运算符,从右执行到左
- 链式赋值: a=b=c=20;a、b、c三个指向同一个地址值
- 参数赋值: +=、-=、*=、/=、//=、%=
- a+=2相当于 a=a+2,其他类似
- 解包赋值: a,b,c=20,30,40 ===> a=20,b=30,c=40,顺序和个数要一致
- 解包赋值常用于变量交换
- 没有解包赋值交换a和b: temp=a;a=b;b=temp
- 有解包赋值一行搞定: a,b=b,a
- 解包赋值常用于变量交换
- 比较运算符
- 比较运算符返回的是bool(False/True)
- 比较对象的value:>,<,>=,<=,!=,==
- 比较对象的id(地址值):is,is not
- 与java不同,java==比较的是地址值
- 布尔运算符
- and 且
- or 或
- not 非
- in 在…里面
- not in 不在…里面
- 位运算符(难但用的少)
- 位与&: 对应数位都是1(true),结果才是1(true),否则位0(false)
- 位或|: 对应数位都是0(false),结果才是0(false),否则位1(true)
- 左移位运算符<<: 高位溢出舍弃,低位补0
- 右移位运算符>>: 低位溢出舍弃,高位补0
运算符的优先级(加括号就行)
present=input('你几岁?')
print(present,type(present))
你几岁?1
1 <class 'str'>
print('5/3=',5/3)
print('5//3=',5//3)
print('5%3=',5%3)
print('2的3次方=',2**3)
print('3的2次方=',3**2)
print('---------------------算术运算符:正负号问题----------------------------')
# 取整//:一正一负向下取整
print('-5//-3=',-5//-3)
print('-5//3=',-5//3)
print('5//-3=',5//-3)
# 取余% : 余数=被除数-除数*商, 其中 商遵循 一正一负上下整
print('-5%-3=',-5%-3) # -5-(-3*1)= -2 ---> -3 + -2 = -5
print('-5%3=',-5%3) # -5-(3*-2)= 1 ---> 3*(-2) + 1 = -5
print('5%-3=',5%-3) # 5-(-3*-2)= -1 ---> -3*(-2) - 1 = 5
5/3= 1.6666666666666667
5//3= 1
5%3= 2
2的3次方= 8
3的2次方= 9
---------------------算术运算符:正负号问题----------------------------
-5//-3= 1
-5//3= -2
5//-3= -2
-5%-3= -2
-5%3= 1
5%-3= -1
# a 与 b 的地址值相同是因为小整数在内存空间的地址是固定的,即内存中有专门的一个区域来存储常量
a=10
b=10
print('a==b为',a==b)
print('a is b为',a is b)
print('a的ID为',id(a))
print('b的ID为',id(b))
list1=[10,11]
list2=[10,11]
print('list1==list2为',list1==list2)
print('list1 is list2为',list1 is list2)
print('list1的ID为',id(list1))
print('list2的ID为',id(list2))
a==b为 True
a is b为 True
a的ID为 4303518736
b的ID为 4303518736
list1==list2为 True
list1 is list2为 False
list1的ID为 4368027328
list2的ID为 4368027520
s = 'nihao'
print('n' in s)
print('b' not in s)
l = [10,20]
print(10 in l)
print(30 not in l)
True
True
True
True
程序的组织结构
顺序结构(略)
选择结构(if)
对象的布尔值
- 获取对象的布尔值:bool()
- 以下对象的布尔值都是False
- False
- 数值0
- None
- 空字符串
- 空列表
- 空数组
- 空字典
- 空集合
单分支结构:如果…就…
语法结构:
if 条件表达式:
条件执行体
双分支结构:如果…不满足…就…
语法结构:
if 条件表达式:
条件执行体1
else:
条件执行体2
多分支结构
语法结构:
if 条件表达式:
条件执行体1
elif:
条件执行体2
elif:
条件执行体N
[elif:]
条件执行体N+1
嵌套if(略)
条件表达式:if-else 的简写
语法结构:x if 判断条件 else y
运算规则:如果判断条件为ture,则执行x并返回x的结果;为false则执行y并返回y的结果
match
# 类似Java中的Switch-case
# Python中的match语句是Python 3.10及以后版本中引入的新特性
x =10
match x:
case 0:
print("x is zero")
case 1:
print("x is one")
case _: # _ 表示匹配所有其他值
print("x is not zero or one")
pass 语句
是什么:语句什么都不做,只是一个占位符,用在语法上需要语句的地方
何时用:在搭建语法结构,但还没想好怎么写代码的时候
用在哪:
- if语句的条件执行体
- for-in语句的循环体
- 定义函数时的函数体
类似java的todo
# 单分支结构
money=1000
m=int(input('请输入取款金额'))
if money>=m: # 和java不一样,java是(),这里是:
money-=m # 执行的语句要缩紧
print('取款成功,余额为:',money)
请输入取款金额500
取款成功,余额为: 500
# 双分支结构
num=int(input("请输入一个整数:"))
if num%2==0:
print("您输入的是一个偶数")
else:
print("您输入的是一个奇数")
请输入一个整数:23
您输入的是一个奇数
# 多分支结构
score = int(input("请输入一个成绩:"))
if(score>=90 and score<=100): # 加()也不影响
print("A")
elif score<90 and score>=80:
print("B")
elif score<80 and score>=70:
print("C")
elif score<70 and score>=60:
print("D")
elif score<60 and score>=0:
print("E")
else:
print("非法数据")
请输入一个成绩:-1
非法数据
# 条件表达式
a = int(input("请输入第一个数字:"))
b = int(input("请输入第二个数字:"))
print(a,'>=',b) if a>=b else print(a,'<',b)
请输入第一个数字:2
请输入第二个数字:3
2 < 3
# pass语句
a= int(input('请输入一个整数'))
if a>0:
pass # 有时候这部分的代码没有想好,但是如果没想好就放在这里,运行程序的时候会报错
else:
pass # 在java中if后面不写语句也是不会报错的
if a>10:{# 如果这里加{}后程序也不报错了
}
请输入一个整数1
循环结构(while/for-in)
rang( ) 函数
- 用于生成一个整数序列
- 创建
range()对象的三种方式range(stop):创建一个【0,stop)之间的整数序列,步长为1range(star,stop):创建一个【start,stop)之间的整数序列,步长为1range(star,stop,step):创建一个【start,stop)之间的整数序列,步长为step- 步长就是相邻的两个数之间的差距
- 返回值是一个迭代器对象,不是列表
- range类型的优点:不管range对象表示的整数序列有多长,所有range对象占用的内存空间都是相同的。
因为仅仅需求存储start,stop和step,只有当用到range对象时,才会去计算序列中的相关元素 - in语not in 判断整数序列是否存在(不存在)制定的整数
# range(stop)
r=range(10);# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
print(r) # range(0, 10)---> 迭代器对象
print(list(r))# 用于查看range对象中的整数序列 ---> list是列表的意思
range(0, 10)
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# range(start,stop)
r=range(1,10);# [1, 2, 3, 4, 5, 6, 7, 8, 9]
print(list(r))# 用于查看range对象中的整数序列 ---> list是列表的意思
[1, 2, 3, 4, 5, 6, 7, 8, 9]
# range(start,stop,step)
r=range(1,10,2);# [1, 3, 5, 7, 9]
print(list(r))# 用于查看range对象中的整数序列 ---> list是列表的意思
[1, 3, 5, 7, 9]
r=range(1,10,2)# [1, 3, 5, 7, 9]
print(1 in r)
print(2 in r)
True
False
while
while 条件表达式:
循环体
条件表达式为true,会一直执行循环体
a = 1
sum=0
while(a<=10):
sum+=a
a+=1
print('sum=',sum)
sum= 55
for-in
for 自定义的变量 in 可迭代的对象:
循环体
- 循环体内不需要访问自定义变量,可以将自定义变量替代为下划线
# 遍历字符串
for item in 'Python':
print(item,end=',')
P,y,t,h,o,n,
# 遍历range
sum=0
for i in range(1,11):
sum+=i
print('sum=',sum)
sum= 55
# 如果循环体中用不到自定义变量,可以 _ 代替
for _ in range(5):
print('人生苦短,我用python')
人生苦短,我用python
人生苦短,我用python
人生苦短,我用python
人生苦短,我用python
人生苦短,我用python
# 水仙花数:abc=a*a*a+b*b*b+c*c*c
for item in range(100,1000):
a=item//100
b=(item//10)%10
c=item%10
if(item-a**3-b**3-c**3==0):
print(item,end=',')
153,370,371,407,
流程控制语句:break与continue
- break:结束循环
- continue:结束当前循环
- 对于二重循环,break与continue用于控制本层循环
else
- if+else:条件表达式不成立,执行else语句
- while+else:没遇得到break,执行else语句
- for-in+else:没遇得到break,执行else语句
# 使用else
for item in range(3):
pwd=int(input("请输入密码:"))
if(pwd==8888):
print('密码正确')
break
else:
print("密码不正确")
else:
print("对不起,三次密码均错误!")
请输入密码:8888
密码正确
# 不使用else要先判断item才能达到上面的效果
for item in range(3):
pwd=int(input("请输入密码:"))
if(pwd==8888):
print('密码正确')
break
else:
print("密码不正确")
if(item==2):
print("对不起,三次密码均错误!")
请输入密码:3
密码不正确
请输入密码:3
密码不正确
请输入密码:3
密码不正确
对不起,三次密码均错误!
嵌套循环
# 99乘法表
for a in range(1,10):
for b in range(1,a+1):
print(b,'x',a,'=',b*a,end='\t')
print()
1 x 1 = 1
1 x 2 = 2 2 x 2 = 4
1 x 3 = 3 2 x 3 = 6 3 x 3 = 9
1 x 4 = 4 2 x 4 = 8 3 x 4 = 12 4 x 4 = 16
1 x 5 = 5 2 x 5 = 10 3 x 5 = 15 4 x 5 = 20 5 x 5 = 25
1 x 6 = 6 2 x 6 = 12 3 x 6 = 18 4 x 6 = 24 5 x 6 = 30 6 x 6 = 36
1 x 7 = 7 2 x 7 = 14 3 x 7 = 21 4 x 7 = 28 5 x 7 = 35 6 x 7 = 42 7 x 7 = 49
1 x 8 = 8 2 x 8 = 16 3 x 8 = 24 4 x 8 = 32 5 x 8 = 40 6 x 8 = 48 7 x 8 = 56 8 x 8 = 64
1 x 9 = 9 2 x 9 = 18 3 x 9 = 27 4 x 9 = 36 5 x 9 = 45 6 x 9 = 54 7 x 9 = 63 8 x 9 = 72 9 x 9 = 81
列表(数组)
列表相当于其他语言的数组
列表的创建:
- [ ]
- 内置函数 list()
list1 = ['hello','o',98,98.3]
print(list1)
list2 = list(['hello',98])
print(list2)
list3 = list("fgeaw")
print(list3)
['hello', 'o', 98, 98.3]
['hello', 98]
['f', 'g', 'e', 'a', 'w']
列表的特点
- 列表元素按顺序有序排列
- 索引映射唯一一个数据
- 正数表示正序,重0开始;负数表示倒叙,重-1开始
- 列表可以存储重复数据,也就是列表不去重
- 任意数据类型混存
- 根据需要动态分配和回收内存,也就是不需要担心元素太多,列表会存不下,会根据数据的多少,动态分配内存
list1=[1,'2',3.0,'four',1]
print(list1[2],list1[-2])
3.0 four
列表元素的查询操作
index():获取列表指定元素的索引- 如果列表中存在N个相同元素,值返回相同元素中的第一个元素的索引
- 如果查询的元素在列表中不存在,则会抛出ValueError
- 还可以在指定的start和stop之间进行查找
- 如果列表中存在N个相同元素,值返回相同元素中的第一个元素的索引
- 获取列表中的单个元素
- 正向索引0到N-1
- 逆向索引-N到-1
- 指定索引不存在,抛出indexError
- 获取类别中的多个元素
- 语法格式:
列表名[start:stop:step] - 切片的结果:原列表片段的拷贝,一个新的类别对象
- 切片的范围:start-stop,不包含stop
- step步长:
- 默认为1,简写
[start,stop] - step为正数:从start开始往后计算切片
[:stop:step]:切片的第一个元素默认是列表的第一个元素[start::step]:切片的最后一个元素默认是列表的最后一个元素
- step为负数:从start开始往前计算切片
[:stop:step]:切片的第一个元素默认是列表的第一个元素[start::step]:切片的最后一个元素默认是列表的最后一个元素
- 默认为1,简写
- 语法格式:
- 判断指定元素在列表中是否存在:
- 元素 in 列表名
- 元素 not in 列表名
- 列表元素遍历
for 迭代变量 in 列表名:
操作
l = ['a',2,'c',4,'a',2]
# index('c',1,5): 表示在index在[1,5)之间(不包括),寻找value='c',返回'c'对应的index
print(l.index('c',1,5))# 2
s=[10,20,30,40,50,60,70,80]
'''
10,20,30,40,50,60,70,80
0 1 2 3 4 5 6 7 正
-8 -7 -6 -5 -4 -3 -2 -1 负
'''
s2=s[0:7]
# 不包含最后一个
print(s2)# [10, 20, 30, 40, 50, 60, 70]
# 不同的对象
print(id(s),id(s2)) # 4425176896 4530576512
# 逆排序
print(s[::-1]) # [80, 70, 60, 50, 40, 30, 20, 10]
'''
取数的步骤:
1-根据正负号判断取数的方向
2-根据start判断从里面开始数
s[1: : 1]的含义:从20(start=1)开始取数,因为step为正数,所以从右边取,又因为stop没写,所以sotp=最后一个元素=80(向右数)
s[1: :-1]的含义:从20开始取,因为step为付数,所以从左边取,又因为stop没写,所以sotp=最后一个元素=10(向左数)
s[7:0:-1]的含义:从80开始取,因为step为付数,所以从左边取,又因为stop=10(不包含10)
s[1:7:-1]的含义:从20开始取,因为step为付数,所以从左边取,又因为stop=60(不包含60),从左边数,数到10,就为止了,数不到60,矛盾
'''
print('s[1: : 1]=',s[1::1])# s[1: : 1]= [20, 30, 40, 50, 60, 70, 80] # 包含最后一个
print('s[1: :-1]=',s[1::-1])# s[1: :-1]= [20, 10]
print('s[7:0:-1]=',s[7:0:-1])# s[7:0:-1]= [80, 70, 60, 50, 40, 30, 20]
print('s[1:7:-1]=',s[1:7:-1])# s[1:7:-1]= []
列表元素的增加操作
append():在列表的末尾添加一个元素,不会创建新对象extend():在列表的末尾至少添加一个元素insert():在列表的任意位置添加一个元素- 切片: 在列表的任意位置至少添加一个元素
# append
l=[1,2,3]
print(l,id(l)) # [1, 2, 3] 4530576512
l.append(4)
print(l,id(l)) # [1, 2, 3, 4] 4530576512
# extend
l2=['a','b']
l.append(l2)
print(l,id(l)) # [1, 2, 3, 4, ['a', 'b']] 4530576512
l.extend(l2)
print(l,id(l)) # [1, 2, 3, 4, ['a', 'b'], 'a', 'b'] 4530576512
# insert
l.insert(1,'c')
print(l,id(l)) # [1, 'c', 2, 3, 4, ['a', 'b'], 'a', 'b'] 4530576512
l[1:] = l2:这是对列表 l 的切片赋值操作:
l[1:]表示从索引1开始到列表末尾的所有元素(即[2, 3])。- 将
l2的内容(即['a', 'b'])赋值给l[1:],替换掉原来的[2, 3]。
l[1:1] = [8, 9]:这是对列表 l 的切片赋值操作:
l[1:1]表示从索引1开始到索引1结束的切片范围。注意,这是一个空切片,因为起始索引和结束索引相同。- 将
[8, 9]赋值给l[1:1],实际上是在索引1的位置插入[8, 9]
# 切片
l=[1,2,3]
print(l,id(l)) # [1, 2, 3] 4424952768
l2=['a','b']
'''
l[1:]=l2
相当于把l从index=1(包含)到位置处切掉:[1]
接着再拼接+['a','b']
'''
l[1:]=l2
print(l,id(l)) # [1, 'a', 'b'] 4424952768
'''
l[1:1] 没有在index=1的位置处+[8,9]
'''
l[1:1]=[8,9]
print(l,id(l)) # [1, 8, 9, 'a', 'b'] 4424952768
列表元素的删除操作
remove():- 一次删除一个元素
- 重复元素只删除第一个
- 元素不存在抛出ValueError
pop():- 删除一个指定索引位置上的元素
- 指定索引不存在抛出IndexError
- 不指定索引,删除列表中最后一个元素
- 切片:一次至少删除一个元素,产生一个新的列表对象
clear():清空列表del:删除列表
# remove
l=[1,1,2,3,4,5,5]
l.remove(1)
print(l) # [1, 2, 3, 4, 5, 5]
# pop
l.pop()
print(l) # [1, 2, 3, 4, 5]
l.pop(2)
print(l) # [1, 2, 4, 5]
l2 = l[0:3]对列表 l 进行切片操作:
l[0:3]表示从索引0开始到索引3之前(不包括索引3)的所有元素。- 切片结果是
[1, 2, 3],并将其赋值给l2。
l[3:] = []对列表 l 进行切片赋值操作:
l[3:]表示从索引3开始到列表末尾的所有元素(即[4, 5])。- 将空列表
[]赋值给l[3:],相当于删除从索引3开始的所有元素。
# 切片:产生新的对象--元素的查找
l=[1,2,3,4,5]
l2=l[0:3]
print(l,id(l)) # [1, 2, 3, 4, 5] 4530576256
print(l2,id(l2)) # [1, 2, 3] 4530510464
# 切片:不产生新的对象--元素的切片增加
l[3:]=[]
print(l,id(l)) # [1, 2, 3] 4530576256
# clear
l=[1,2,3,4,5]
l.clear()
print(l) # []
del l
# print(l) # 已经没有这个对象,再打印就报错了
列表元素的修改操作
- 为指定索引的元素赋予新的值,变化的是地址值
- 为指定的切片赋予新的值
l = [1,2,3,4]
l[0]=10
print(l) # [10, 2, 3, 4]
l[1:3]=[20,30] # 把1-3(不包括3)的位置的元素替换成[20,30]
print(l) # [10, 20, 30, 4]
列表元素的排序操作
sort( ):默认元素按照从小到大进行升序排列;指定reverse=true,进行降序排列sorted( )为内置函数。默认升序;指定reverse=true,进行降序排列- 与sort的区别:sorted会生成一个新的对象,原列表不发生任何改变
l=[3,4,2,1,6,5]
print(l,id(l)) # [3, 4, 2, 1, 6, 5] 4539524736
l.sort()
print(l,id(l)) # [1, 2, 3, 4, 5, 6] 4539524736
l.sort(reverse=True)
print(l,id(l)) # [6, 5, 4, 3, 2, 1] 4539524736
l=[3,4,2,1,6,5]
print(l,id(l)) # [3, 4, 2, 1, 6, 5] 4541143808
l2=sorted(l)
print(l2,id(l2)) # [1, 2, 3, 4, 5, 6] 4539489408
l3=sorted(l,reverse=True)
print(l3,id(l3)) # [6, 5, 4, 3, 2, 1] 4538265728
列表生成式
语法格式:
list=[f(i) for i in 可迭代对象 ]
i:属于自定义变量,来自于可迭代对象里面的元素
f(i): 列表元素表达式,生成list的每一个元素,不能是赋值操作
list:生成的新的列表
l1=[i for i in range(5)]
print(l1) # [0, 1, 2, 3, 4]
a=2
l2=[a*i for i in range(5)]
print(l2) # [0, 2, 4, 6, 8]
ls=[-1,-2,-3,-4,-5,-6]
#l2=[ls[i]=i for i in range(5)]# 不能是赋值操作
l2=[ls[i] for i in range(5)]
print(l2) # [-1, -2, -3, -4, -5]
l3=[2 for i in range(5)]# 可以和i无关
print(l3) # [2, 2, 2, 2, 2]
l3=[-1*i for i in ls]# 不一定要是range
print(l3) # [1, 2, 3, 4, 5, 6]
字典
什么是字典
- python内置的数据结构之一,与列表一样是一个可变序列
- 以键值对的方式存储数据,字典是一个无序的序列
- 与java中的map类似
字典的创建
- 使用花括号
{} - 使用
dist()
a={"张三":100,"wang":20}
print(a,type(a)) # {'张三': 100, 'wang': 20} <class 'dict'>
s=dict(name='jack',age=20)
print(s,type(s)) # {'name': 'jack', 'age': 20} <class 'dict'>
字典元素的获取
[ ]: 如果没有对应的key会报错——keyErrorget()方法:没有key的时候不会报错,会返回None,也可以设置默认值
a={'a':1,'b':2}
print(a['a']) # 1
#print(a['c'])#KeyError: 'c'
print(a.get('a')) # 1
print(a.get('c')) # None
print(a.get('c',0))# 0 - 设置的默认值
字典元素的增删改
- key的判断
- in:存在为true
- not in: 不存在为true
- 删除 del 字典[key]
- 清空 clear
- 新增与修改 字典[key]=值
a={'a':1,'b':2,'c':3}
print('a'in a,'a' not in a) # True False
del a['a']
print(a) # {'b': 2, 'c': 3}
a.clear()
print(a) # {}
a['d']=4
print(a) # {'d': 4}
a['d']=5
print(a) # {'d': 5}
获取字典视图
keys():获取字典的所有keyvalues():获取字典的所有valueitems(): 获取字典的所有键值对
a={'a':1,'b':2,'c':3}
keys=a.keys()
print(type(keys),keys) # <class 'dict_keys'> dict_keys(['a', 'b', 'c'])
print(list(keys))# 可以通过list函数把dict_keys类型转换成列表 # ['a', 'b', 'c']
a={'a':1,'b':2,'c':3}
values=a.values()
print(type(values),values) # <class 'dict_values'> dict_values([1, 2, 3])
print(list(values))# 可以通过list函数把dict_values类型转换成列表 # [1, 2, 3]
a={'a':1,'b':2,'c':3}
items=a.items() # <class 'dict_items'> dict_items([('a', 1), ('b', 2), ('c', 3)])
print(type(items),items)
# 可以通过list函数把dict_values类型转换成列表 其中( ) 称为元组
print(list(items)) # [('a', 1), ('b', 2), ('c', 3)]
字典元素的遍历
a={'a':1,'b':2,'c':3}
for item in a: # 获取的是字典元素的key
print(item,a[item],a.get(item))
a 1 1
b 2 2
c 3 3
字典元素的特点
- key不允许重复,value可以重复
- 字典只能够的元素是无序的
- 字典中的key必须是不可变对象
- 字典也可以根据需要动态地伸缩,不需要考虑存不了的情况
- 字典会浪费较大的内存,是一种用空间换时间的数据结构
字典生成式
- 内置函数
zip():可以将迭代的对象打包成一个元组,然后返回由这些元组组成的列表 - 字典生成式:
{ key:value for key, value in zip(迭代对象1,迭代对象2}- key对应迭代对象1的元素;value对应迭代对象2的元素
items=['fruits','books','others']
price=[96,78,85]
lst1= zip(items,price)
lst2= zip(price,items)
# 返回的是一个迭代器对象,只能遍历一次
print(lst1,type(lst1)) # <zip object at 0x10eb28dc0> <class 'zip'>
print(lst2,type(lst2)) # <zip object at 0x10e72ae40> <class 'zip'>
print(list(lst1)) # [('fruits', 96), ('books', 78), ('others', 85)]
print(list(lst2)) # [(96, 'fruits'), (78, 'books'), (85, 'others')]
# list 内部是有遍历的,上面用了一次,这次在用就为{}
print(list(lst1)) # []
items=['fruits','books','others']
price=[96,78,85]
lst= zip(items,price)
dct={key:value+10 for key,value in lst}
print(dct) # {'fruits': 106, 'books': 88, 'others': 95}
元组
什么是元组
- python内置的数据结构之一,是一个不可变序列
- 不可变序列与可变序列
- 不可变序列:没有增删改操作,如字符串和元组
- 可变序列:对元素可以执行增删改操作,对象地址值不发生更改,如列表和字典
元组的创建
- 使用小括号
() - 使用内置函数
tuple() - 小括号也可以省略
- 但如果元组中只有一个元素,小括号和逗号都不能省略
- 空元组:
()和tuple()
t = (10,"tt")
print(t,type(t)) # (10, 'tt') <class 'tuple'>
d = tuple((10,"tt"))
print(d,type(d)) # (10, 'tt') <class 'tuple'>
t2 = "t2",12,32.3
print(t2,type(t2)) # ('t2', 12, 32.3) <class 'tuple'>
#t3 = tuple("t3",20) # 这个不行
#print(t3,type(t3))
t4 = ("t4")
print(t4,type(t4))# t4 <class 'str'> # 被认为是字符串
t5 = ("t5",)
print(t5,type(t5)) # ('t5',) <class 'tuple'>
t6=()
print(t6,type(t6)) # () <class 'tuple'>
t7=tuple()
print(t7,type(t7)) # () <class 'tuple'>
为什么要将元组设计成不可变序列
- 一旦创建不可变序列,数据就不可修改,避免因修改数据而造成错误
- 在多任务多的环境下,同时操作对象时就不需要加锁
元组中存储的是对象的引用
所以在元组中,不变的是对象的引用。但是我们可以改变改引用多指向的值。
t = (1,[2,3],4)
print(t,type(t[1]),id(t[1])) # (1, [2, 3], 4) <class 'list'> 4541580672
#t(0) = 5# 会报错
t[1].append(5)
print(t,type(t[1]),id(t[1])) # (1, [2, 3, 5], 4) <class 'list'> 4541580672
t[1][0]=6
print(t,type(t[1]),id(t[1])) # (1, [6, 3, 5], 4) <class 'list'> 4541580672
元组的遍历
t = (1,[2,3],4)
for item in t:
print(item,end="-->")
1-->[2, 3]-->4-->
集合
什么是集合
- 是python的内置数据结构
- 可变序列
- 集合是没有value的字典
- 特点:去重于无序
集合的创建方式
{}set()- 把序列range转为集合
- 把列表转为集合
- 把元组转为集合
- 把字符串序列转为集合
- 把集合转成新的集合
- 空集合:只能使用
set(),使用{}得到的是一个字典
s = {1,1,2,3,4,5,5}# 不允许重复
print(s) # {1, 2, 3, 4, 5}
s2=set(range(6))
print(s2,type(s2)) # {0, 1, 2, 3, 4, 5} <class 'set'>
l=[1,2,2,3,3]
s3=set(l)
print("l=",l) # l= [1, 2, 2, 3, 3]
print("s3=",s3)# 去重 # s3= {1, 2, 3}
t=(56,45,9,100)
print(t) # (56, 45, 9, 100)
print(set(t))# 集合是无序的 # {56, 9, 100, 45}
print(set("python"))# 集合是无序的 # {'t', 'n', 'h', 'p', 'o', 'y'}
print(set(set("python"))) # {'t', 'n', 'h', 'p', 'o', 'y'}
s={}
print(s,type(s))
s2 = set()
print(s2,type(s2))
{} <class 'dict'>
set() <class 'set'>
集合的相关操作
判断操作:in或not in
新增操作
add:一次添加一个元素update:至少添加一个元素
修改操作
remove:一次删一个指定元素,如果指定元素不存在,抛keyerrodiscard:一次删一个指定元素,如果指定元素不存在,不抛异常pop:一次删除任意一个元素,无参clear:清空集合
s = {"1",1,3,4}
print(s) # {'1', 3, 4, 1}
s.add("t")
print(s) # {'1', 1, 3, 4, 't'}
s.update({5,6})# 集合
s.update([7,8])# 列表
s.update((9,10))# 元组
print(s) # {'1', 1, 3, 4, 5, 6, 7, 8, 9, 10, 't'}
s.remove(1)
s.discard(1)
print(s) # {'1', 3, 4, 5, 6, 7, 8, 9, 10, 't'}
s.pop()
print(s) # {3, 4, 5, 6, 7, 8, 9, 10, 't'}
s.clear()
print(s) # set()
集合间的关系
- 两个集合是否相等:
==/!=(判断元素是否相等) - 一个集合是否是另一个集合的子集:
issubsetA.issubset(B):A是B的子集么?A包含于B么?
- 一个集合是否是另外一个集合的超集:
issupersetA.issuperset(B):A是B的超集么?A包含B么?
- 两个集合是否有交集:
isdisjoint- 是否没有交集
s1={1,2,3}
s2={1,2,3,4}
s3={4,5,6}
print(s1==s2) # False
print(s1!=s2) # True
print(s1.issubset(s2)) # True
print(s2.issuperset(s1)) # True
print(s2.isdisjoint(s1))# false - 有交集
print(s2.isdisjoint(s3))# false - 有交集
集合的数据操作
- 交集操作:
intersection和& - 并集操作:
union和| - 差集操作:
difference和- - 对称差集操作:
symmetry_difference和^
s1 = {1,2,3}
s2 = {2,3,4}
si1=s1.intersection(s2)
si2=s1&s2
print("交集:",si1,si2) # 交集: {2, 3} {2, 3}
su1=s1.union(s2)
su2=s1|s2
print("并集",su1,su2) # 并集 {1, 2, 3, 4} {1, 2, 3, 4}
sd1=s1.difference(s2)
sd2=s1-s2
print("s1-s2的差集:",sd1,sd2) # s1-s2的差集: {1} {1}
ssd1=s1.symmetric_difference(s2) # s1和s2的对称差集: {1, 4} {1, 4}
ssd2=s1^s2
print("s1和s2的对称差集:",ssd1,ssd2)
集合生成式
# 列表生成式
ls=[i*i for i in range(10)]
print(ls) # [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
# 集合生成式
st={i*i for i in range(10)}
print(st) # {0, 1, 64, 4, 36, 9, 16, 49, 81, 25}
列表、字典、元组、结合总结
| 数据结构 | 是否可变 | 是否重复 | 是否有序 | 定义符号 |
|---|---|---|---|---|
| 列表list | 可变 | 可重复 | 有序 | [ ] |
| 字典dist | 可变 | key不可重复 value可重复 |
无序 | {key:value} |
| 元组tuple | 不可变 | 可重复 | 有序 | ( ) |
| 集合set | 可变 | 不可重复 | 无序 | { } |
字符串
字符串的驻留机制
字符串是python的基本数据类型,是一个不可变的字符序列
什么叫字符串驻留机制
仅保存一份相同且不可变字符串的方法,不同的值被存放在字符串的驻留池中,python的驻留机制对相同的字符串只保留一份拷贝,后续创建相同的字符串时,不会开辟新的内存空间,而是把该字符串的地址赋给新创建的变量驻留机制的几种情况
- 字符串的长度为1或0时
- 字符串符合标识符的规则:数字、字母、下划线
- 字符串只在编译时驻留,而非运行时
- [-5,256]之间的整数数字
sys中的intern方法强制2个字符串指向同一个对象
PyCharm对字符串进行了优化处理
字符串驻留机制的优缺点
当需要值相同的字符串时,可以之间从字符串池中拿来使用,避免频繁的创建和销毁,提升效率和节约内存,因此拼接字符串和修改字符串时会比较影响性能。
在需要进行字符串拼接时建议使用str类型的join方法,而非+,首先字符串为不可变序列,每一个新的字符串都会生成一个新的对象。
a+b+c:a+b生成一个对象,接着+c又生成一个对象而
"".join(a,b,c)会计算出所有字符的长度,然后在拷贝,只new一次对象,效率比+要高
a = 'abc'
b = "abc"
c = '''abc'''
print(id(a)) # 4384582768
print(id(b)) # 4384582768
print(id(c)) # 4384582768
# 字符串的长度为1或0时
a=''
b=''
print(a is b) # True
c='w'
d='w'
print(c is d) # True
# 字符串符合标识符的规则
a='1_a'
b='1_a'
print(a is b) # True
# 对于包含特殊字符(如 %)的字符串,Python 可能不会进行驻留优化
#
c='1_a%'
d='1_a%'
print(c is d) # False
# 字符串只在编译时驻留,而非运行时
a = 'abc'
b = 'a'+'bc'
# 由于 Python 对字符串进行了驻留优化(interning),相同内容的字符串可能会共享内存地址。
# 因此,a 和 b 的内存地址可能相同。
print(a,id(a)) # abc 4384582768
print(b,id(b)) # abc 4384582768
# 上面代码中直接定义的字符串(即字面量字符串)会被驻留
# 下面中 d 的值 是在运行时确定的,所有不会被驻留
c = 'a'
d =c.join('bc')
print(c,id(c))# id不同 # a 4384821936
# join() 方法创建的新字符串
print(d,id(d))# id不同 # bac 4538639984
# s1 是在运行时确定的,所有也不会被驻留
s1 = input("请输入:") # abc
s2 = 'abc'
print(s1,id(s1)) # abc 4408545072
print(s2,id(s2)) # abc 4398155696
import sys
a = 'abc%'
b = 'abc%'
print(a is b) # False
c = sys.intern(a)# 把a的地址给c
print(a is c) # True
字符串的常用操作
查询操作
index:找到字串中第一次出现的位置,从前面开始找,找不到valueError,返回intrindex:找到字串中最后一次出现的位置,从后面开始找,找不到valueError,返回intfind:找到字串中第一次出现的位置,从前面开始找,找不到不报错,返回int,找不到返回-1rfind:找到字串中最后一次出现的位置,从后面开始找,找不到不报错,返回int,找不到返回-1
'''
p y t h o n , p y t h o n
0 1 2 3 4 5 6 7 8 9 10 11 12
'''
str='python,python'
a=str.index("on")
print(a,type(a)) # 4 <class 'int'>
b=str.rindex("on")
print(b,type(b)) # 11 <class 'int'>
#a=str.index("onn")#ValueError: substring not found
#a=str.rindex("onn")#ValueError: substring not found
c=str.find("on")
print(c,type(c)) # 4 <class 'int'>
d=str.find("onn")
print(d,type(d)) # -1 <class 'int'>
e=str.rfind("on")
print(e,type(e)) # 11 <class 'int'>
e=str.rfind("onn")
print(e,type(e)) # -1 <class 'int'>
字符串的大小写转换操作
upper:把字符串中所有字符转成大写lower:把字符串中所有字符转成小写swapcase:大写转小写,小写转大写capitalize:第一个字符串大写,后面小写title:每个单词的首字母大写,其余的字符串为小写
str = 'heLLo,woRLD'
a=str.upper()
print(a,type(a)) # HELLO,WORLD <class 'str'>
b=str.lower()
print(b,type(b)) # hello,world <class 'str'>
c=str.swapcase()
print(c,type(c)) # HEllO,WOrld <class 'str'>
d=str.capitalize()
print(d,type(d)) # Hello,world <class 'str'>
e=str.title()
print(e,type(e)) # Hello,World <class 'str'>
字符串内容对齐操作
center:- 居中对齐
- 第1个参数:指定宽度
- 第2个参数:指定填充,可选,默认为空格
- 如果设置宽度小于实际宽度,返回原字符串
ljust:- 左对齐
- 第1个参数:指定宽度
- 第2个参数:指定填充,可选,默认为空格
- 如果设置宽度小于实际宽度,返回原字符串
rjust:- 右对齐
- 第1个参数:指定宽度
- 第2个参数:指定填充,可选,默认为空格
- 如果设置宽度小于实际宽度,返回原字符串
zfill:- 右对齐
- 左边用0填充
- 只接受一个参数,用于指定字符串的宽度
- 如果设置宽度小于实际宽度,返回原字符串
str='hello'
a=str.center(10)
print(a,type(a))
a=str.center(10,'*')
print(a,type(a))
b=str.ljust(10,'*')
print(b,type(b))
c=str.rjust(10,'*')
print(c,type(c))
d=str.zfill(10)
print(d,type(d))
hello <class 'str'>
**hello*** <class 'str'>
hello***** <class 'str'>
*****hello <class 'str'>
00000hello <class 'str'>
字符串劈分操作
split:- 从字符串的左边开始劈分,默认的劈分字符是空字符串,返回的值都是一个列表
- 以通过参数
sep指定劈分字符串的劈分符 maxsplit指定字符串时的最大劈分次数,在经过最大劈分之后,剩余的字串会单独作为一部分
rsplit:- 从字符串的右边开始劈分,默认的劈分字符串是空哥字符串,返回的值都是一个列表
- 以通过参数sep指定劈分字符串的劈分符
- maxsplit指定字符串时的最大劈分次数,在经过最大劈分之后,剩余的字串会单独作为一部分
str='h-e-l-l-o'
ls=str.split("-")#默认sep
print(ls,type(ls))
ls=str.split(sep="-")
print(ls,type(ls))
ls=str.split("-",maxsplit=3)# 切3次
print(ls,type(ls))
['h', 'e', 'l', 'l', 'o'] <class 'list'>
['h', 'e', 'l', 'l', 'o'] <class 'list'>
['h', 'e', 'l', 'l-o'] <class 'list'>
判断字符串操作的方法
isidentifier:判断是不是合法标识符- 标识符有字母、数字、下划线组成。
- 所有标识符可以包括英文、数字以及下划线(
_),但不能以数字开头。 - 以下划线开头的标识符是有特殊意义的。以单下划线开头(
_foo)的代表不能直接访问的类属性,需通 过类提供的接口进行访问,不能用”from xxx import *”而导入; - 以双下划线开头的(
__foo)代表类的私有成员; - 以双下划线开头和结尾的(
__foo__)代表python里 特殊方法专用的标识,如__init__()代表类的构造函数。
isspace:判断字符串是否全部由空白字符组成:回车、换行、水平制表符,有就为False,没有就为Trueisalpha:判断字符串是否全部由字母字串isdecimal:判断指定字符串是否全部由十进制的数字组成isnumeric:判断指定的字符串是否全部由数字组成isalnum:判断指定字符串是否由字母和数字组成
print("1_x","1_x".isidentifier())
print("张三","张三".isidentifier())# 汉字也可以为标识符
print("a%","a%".isidentifier())
print("\t","\t".isspace())# True
print("a\t","a\t".isspace())# False,不是全部由空字符串组成
print("aSDb","aSDb".isalpha())
print("aSDb!","aSDb!".isalpha())
print("100","100".isdecimal())
print("001","001".isdecimal())# 001-也是true
print("00四","00四".isdecimal())# False
print("00四","00四".isnumeric())# True
print("ab12","ab12".isalnum())# True
print("ab12章","ab12章".isalnum())# True
print("ab12!","ab12!".isalnum())# False
张三 True
a% False
True
a False
aSDb True
aSDb! False
100 True
001 True
00四 False
00四 True
ab12 True
ab12章 True
ab12! False
字符串的操作的其他方法
replace:- 第1个参数:被替换的字串
- 第2个参数:指定替换字串的字符串
- 第3个参数:最大替换次数
- 返回:替换后得到的字符串
join:将列表或元组的字符串合并成一个字符串
str="helloll"
s=str.replace("l","z")
print(s) # hezzozz
s=str.replace("l","z",3)
print(s) # hezzozl
ls=['1','sd','cd']
s=''.join(ls)
print(s) # 1sdcd
s='-'.join(ls)# 链接
print(s) # 1-sd-cd
# 必须要全为字符串,否则会报错
#tp=("a",2,"c")#TypeError: sequence item 1: expected str instance, int found
tp=("a","2","c")
t='-'.join(tp)
print(t) # a-2-c
字符串的比较操作
- 运算符:>,>=,<,<=,==,!=
- 比较规则:一个一个字符串进行比较
- 比较原理:比较的oridnal value(原始值),即Unicode值,其中Unicode的前128位数ASCII码
- 调用内置函数
ord可以得到指定字符的ordinal value - 调用内置函数
chr时指定ordinal value 可以得到其对应的字符
print("apple">"app") # True
print("apple"<="app") # False
print("apple"!="app") # True
# 获取原始值
print(ord("a"),ord('b')) # 97 98
print(ord("章"),ord('张')) # 31456 24352
# == 比较的是value;is比较的是id
a=b='app'
c='app'
print(a==c,a is c)# True True 都相等时因为字符串的驻留机制
字符串的切片操作
s[:5]:从头开始到5结束,不包含5s[6:]:从6开始到尾结束,包含6s[:5:-1]:负数的开头是最右边,从最右边开始,到index=5的地方结束,不包含5s[6::-1]:负数的结束是最左边,从index=6的地方开始(包含6)直到结束s[:-5:-1]:负数的开头是最右边,从最右边开始,到index=-5的地方结束,不包含5s[-6::-1]:负数的结束是最左边,从index=-6的地方开始(包含6)直到结束
# -9 -8 -7 -6 -5 -4 -3 -2 -1
#. 零 一 二 三 四 五 六 七 八
str='零一二三四五六七八'
a=str[:5]
b=str[6:]
print(a)# 零一二三四
print(b) # 六七八
print('------------------')
c=str[:5:-1]
d=str[6::-1]
print(c) # 八七六
print(d) # 六五四三二一零
print('------------------')
e=str[:-5:-1]
f=str[-6::-1]
print(e) # 八七六五
print(f) # 三二一零
格式化字符串
使用 format() 方法
语法:"{:[填充字符][对齐方式][宽度][.精确度][类型]}".format(值)
# 设置宽度
print("{:10}".format(123)) # 输出 ' 123'(默认右对齐)
print("{:<10}".format(123)) # 输出 '123 '(左对齐)
print("{:^10}".format(123)) # 输出 ' 123 '(居中对齐)
print("{:*>10}".format(123)) # 输出 '*******123'(右对齐,填充*)
# 设置精确度
print("{:.2f}".format(3.14159)) # 输出 '3.14'(保留2位小数)
print("{:.5}".format("Hello World")) # 输出 'Hello'(截取前5个字符)
print('{0:.3}'.format(7451.4566))#7.45e+03=7450:整数位数>=3会用科学记数法
#ValueError: Precision not allowed in integer format specifier
#print('{0:.3}'.format(7585))整数不能用.3的格式
{}作占位符:
{num}:num是第几个参数,从0开始
str2="我叫{1:^10},今年{0:_^4}岁,高考考了{2:.2f}分"
print(str2.format(20,'张三',675.5)) # "我叫 张三 ,今年_20_岁,高考考了675.50分"
使用 f-string(Python 3.6+)
语法:f"{值:[填充字符][对齐方式][宽度][.精确度][类型]}"
# 设置宽度
num = 123
print(f"{num:10}") # 输出 ' 123'(默认右对齐)
print(f"{num:<10}") # 输出 '123 '(左对齐)
print(f"{num:^10}") # 输出 ' 123 '(居中对齐)
print(f"{num:*>10}") # 输出 '*******123'(右对齐,填充*)
# 设置精确度
pi = 3.14159
print(f"{pi:.2f}") # 输出 '3.14'(保留2位小数)
text = "Hello World"
print(f"{text:.5}") # 输出 'Hello'(截取前5个字符)
{}作占位符:
f{pramName}:pramName:变量参数名,f是固定格式
name='张三'
age=20
score=675.5
str3=f"我叫{name:^10},今年{age:_^4}岁,高考考了{score:.2f}分"
print(str3.format(age,name,score)) # 我叫 张三 ,今年_20_岁,高考考了675.50分
使用 % 格式化
%作占位符:
%s:字符串%i或%d:整数%f:浮点数- 参数值是依次对应的
语法:"%[宽度][.精确度][类型]" % 值
%10d:表示宽度是10%.3f:表示精度是小数点后3位%10.3f:表示宽度为10,精度是小数点后3位
# 设置宽度
print("%10d" % 123) # 输出 ' 123'(默认右对齐)
print("%-10d" % 123) # 输出 '123 '(左对齐)
print('%10.3d'%10)#不够补0 # 输出 ' 010'
# 设置精确度
print("%.2f" % 3.14159) # 输出 '3.14'(保留2位小数)
print('%10.3f'%675.55555) #会四舍五入 输出' 675.556'
print("%.5s" % "Hello World") # 输出 'Hello'(截取前5个字符)
str1="我叫%10s,今年%4d岁,高考考了%.2f分"
# 这里的 % 是固定符号
print(str1 % ("张三",20,675.5)) # 我叫 张三,今年 20岁,高考考了675.50分
字符串的编码转换
- 为什么需要字符串的编码转换:计算机之间是通过byte字节传输
- 编码与解码:
- 编码:字符串转换为二进制数据(bytes)—— encode
- 解码:将bytes类型的数据转换为字符串类型 —— decode
s="天涯共此时"
# 用GBK编码
a=s.encode(encoding='GBK')
print(a,type(a))
b=a.decode(encoding='GBK')
print(b,type(b))
#使用不同的格式去解码会报错
#c=a.decode(encoding='UTF-8')#UnicodeDecodeError
b'\xcc\xec\xd1\xc4\xb9\xb2\xb4\xcb\xca\xb1' <class 'bytes'>
天涯共此时 <class 'str'>
函数
函数的创建:
def 函数名(参数):
函数体
「return xxx」
def sub(a,b):
c=a-b;
return c
res=sub(10,1)
print(res) # 9
函数的参数传递
- 位置实参:根据参数的位置进行实参传递
- 关键字实参:根据形参名称进行实参传递
def sub(a,b):
c=a-b;
return c
res=sub(b=10,a=1)
print(res) # -9
函数调用的参数传递内存分析:传递的是地址值
def fun(arg1,arg2):
print('----------------------------------')
print('arg1=',arg1,'id(arg1)=',id(arg1));
print('arg2=',arg2,'id(arg2)=',id(arg2));
arg1=100;
arg2.append(100)
print('arg1=',arg1,'id(arg1)=',id(arg1));
print('arg2=',arg2,'id(arg2)=',id(arg2));
print('----------------------------------')
a=10
b=[10,20]
print('a=',a,'id(a)=',id(a));
print('b=',b,'id(b)=',id(b));
fun(a,b)
print('a=',a,'id(a)=',id(a));
print('b=',b,'id(b)=',id(b));
a= 10 id(a)= 4382432272
b= [10, 20] id(b)= 4546440192
----------------------------------
arg1= 10 id(arg1)= 4382432272
arg2= [10, 20] id(arg2)= 4546440192
arg1= 100 id(arg1)= 4382435152
arg2= [10, 20, 100] id(arg2)= 4546440192
----------------------------------
a= 10 id(a)= 4382432272
b= [10, 20, 100] id(b)= 4546440192
fun之前:
a的地址值:2272->10;
b的地址值:0192->[10, 20];
调用fun,传入的是地址值
arg1=a->2272
arg2=b->0192
arg1=100:
100在是一个新的内存空间,arg1这个变量等于是换了一个地址:5152
arg2.append(100):
这个操作操作的仍是0192这个内存空间的数据
调用之后:
a= 10:因为fuc这个函数没有对2272这个内存空间的数据进行任何操作,所以不变
b= [10, 20, 100]:因为arg2.append(100)对0192这个内存的数据进行了操作,所以变了
函数的返回值
- 如果函数没有返回值,retrun可以省略不写
- 可以直接使用return结束方法
- 返回一个参数时,返回的是该返回值类型
- 返回多个值时,结构为元组
# 原例子中这里写的是num,我一开始以为是填一个数,但往后看代码才发现应该填一个list
# 这反映了弱类型语言的劣势,如果参数名字不见名知意,我就不知道要传什么类型的参数
def fun(numList):
odd=[]#存奇数
even=[]#存偶数
for i in numList:
if i%2:#i%2==0 0和True可以相互转换,C的特点
even.append(i)
else:
odd.append(i)
return odd,even
num=[10,23,24,4,12,33,3]
res=fun(num)
print(res,type(res)) # ([10, 24, 4, 12], [23, 33, 3]) <class 'tuple'>
函数的参数定义
默认值参数:print的end的参数的默认值为:\t
# 默认值设置
def fun(a,b=0):
print(a,b)
fun(10) # 10 0
fun(11,12) # 11 12
个数可变的位置参数:
- 定义函数时,可能无法事先确定传递的位置参数的个数,这时可以使用可变的位置参数
- 使用
*定义个数可变的位置参数 - 结果为一个元组
- 只能有一个可变位置参数
#个数可变的位置参数
#def fun(*args,*a):过不了编译
def fun(*args):
print(args,type(args))
fun(10)
fun(10,'ab',12)
print('---------------------')
# 可变位置参数+另一个形参时,需要使用关键字传参,否则会报错
# TypeError: fun() missing 1 required keyword-only argument: 'a'
def fun1(*args,a):
print(args,type(args),'a=',a)
fun1(10,a=0)
fun1(10,'ab',12,a=0)
(10,) <class 'tuple'>
(10, 'ab', 12) <class 'tuple'>
---------------------
(10,) <class 'tuple'> a= 0
(10, 'ab', 12) <class 'tuple'> a= 0
个数可变的关键字形参
- 定义函数时,无法事先确定传递的关键字实参的个数,这时可以使用可变的关键字形参
- 使用
**表示个数可变的关键字形参 - 结果为一个字典
- 只能有一个可变关键字参数
# 个数可变的关键字形参
#def fun(**args,**a):过不了编译
def fun(**args):
print(args,type(args))
# 必须使用关键字穿参,否则报错
# TypeError: fun() takes 0 positional arguments but 3 were given
# fun(10,20,30)
fun(a=10,b=20,c=30)
# 不能这么定义:def fun2(**args,a),否则会报语法错误
def fun2(a,**args):
print(args,type(args),'a=',a)
#fun2(d=10,b=20,c=30)必须传入a,否则会报错:
#TypeError: fun2() missing 1 required positional argument: 'a'
fun2(a=10,b=20,c=30)
{'a': 10, 'b': 20, 'c': 30} <class 'dict'>
{'b': 20, 'c': 30} <class 'dict'> a= 10
# 可变位置参数+可变关键字参数
#def fun(**args,*arg):没有这种形式
def fun(*args1,**args2):
print(args1,type(args1))
print(args2,type(args2))
print('------------------------')
fun()
fun(10,11)
fun(a=10,b=11)
# fun(10,a=20,30,b=40)SyntaxError: positional argument follows keyword argument
fun(10,20,a=30,b=40)
# 如果位置参数和关键字参数都要传,位置参数必须在前面
# fun(a=1,b=2,"s","b")SyntaxError: positional argument follows keyword argument
fun("s","b",a=1,b=2)
() <class 'tuple'>
{} <class 'dict'>
------------------------
(10, 11) <class 'tuple'>
{} <class 'dict'>
------------------------
() <class 'tuple'>
{'a': 10, 'b': 11} <class 'dict'>
------------------------
(10, 20) <class 'tuple'>
{'a': 30, 'b': 40} <class 'dict'>
------------------------
('s', 'b') <class 'tuple'>
{'a': 1, 'b': 2} <class 'dict'>
------------------------
实参与形参
- 在函数定义时,定义的是形参
- 在函数调用时,传入的是实参
函数调用时使用*:把序列中的每一个元素转换为位置实参
# 多个位置实参
def fun(a,b,c):
print(a,b,c)
fun(1,2,3)
ls=[1,2,3]
fun(*ls)
print('---------')
def fun2(*arg):
print(arg)
fun2(ls)#([1, 2, 3],) 把ls作为一个参数
fun2(*ls)
'''
少了会报错:TypeError: fun() missing 1 required positional argument: 'c'
ls2=[1,2]
fun(*ls2)
'''
print('---------')
1 2 3
1 2 3
---------
([1, 2, 3],)
(1, 2, 3)
---------
函数调用时使用**:把字典中的每一个键值对转换为关键字实参
# 多个关键字传参
def fun(a,b,c):
print(a,b,c)
print('---------')
fun(a=1,b=2,c=3)
dis={"a":1,'b':2,'c':3}
fun(**dis)
1 2 3
---------
1 2 3
---------
def fun(a,b,*,c,d):表示之后的参数只能采用关键字传参
# 指定关键字传参
def fun(a,b,*,c,d):
print(a,b,c,d)
#fun(10,20,30,40)#TypeError: fun() takes 2 positional arguments but 4 were given
fun(10,20,c='a',d='c')
10 20 a c
变量的作用域
- 局部变量:函数内定义的
- 全局变量:
- 函数外定义的
- global修饰的
a=1;
def fun (param):
b=10
global d
d=20
c=param+a # 全局变量可以在函数内使用
return c
#TypeError: unsupported operand type(s) for +: 'int' and 'list'
'''b是局部变量,不能在函数外用'''
#res=fun(5)+b
res=fun(5)+d# d是全局变量,可以拿出来用
print(res) # 26
递归函数
- 什么是递归:函数自己调自己
- 递归的组成部分:递归的调用与递归的终止条件
- 递归的调用过程:
- 每递归调用一次函数,都会在栈内存分配一个栈帧
- 每执行完一次函数,都会释放相应的空间
- 递归的优缺点:
- 缺点:占用内存多,效率低下
- 优点:思路和代码简单
# 阶乘
def fun(n):
if(n==1):
return 1
return fun(n-1)*n
print(fun(5)) # 120
# 斐波那契数列
# 1,1,2,3,5,8...
# a1=1;a2=1 f(n)=f(n-1)+f(n-2)
def fun(n):
if(n==1 or n==2):
return 1
return fun(n-1)+fun(n-2)
print(fun(6)) # 8
内置函数
Python 3 提供了丰富的内置函数(Built-in Functions),这些函数无需导入任何模块即可直接使用。
输入输出
- **
print(\*objects, sep=' ', end='\n', file=sys.stdout, flush=False)**打印输出内容。 - **
input(prompt)**从标准输入读取一行文本。
类型转换
- **
int(x, base=10)**将x转换为整数。 - **
float(x)**将x转换为浮点数。 - **
str(object)**将对象转换为字符串。 - **
bool(x)**将x转换为布尔值。 - **
list(iterable)**将可迭代对象转换为列表。 - **
tuple(iterable)**将可迭代对象转换为元组。 - **
set(iterable)**将可迭代对象转换为集合。 - **
dict(\**kwargs)**创建字典。
数学运算
- **
abs(x)**返回x的绝对值。 - **
pow(x, y, z=None)**返回x的y次方,如果提供z,则返回x**y % z。 - **
round(number, ndigits=None)**对number进行四舍五入,保留ndigits位小数。 - **
sum(iterable, start=0)**对可迭代对象求和。 - **
min(iterable, \*args, key=None)**返回可迭代对象中的最小值。 - **
max(iterable, \*args, key=None)**返回可迭代对象中的最大值。 - **
divmod(a, b)**返回(a // b, a % b)。
迭代与序列操作
len(s) 返回对象的长度。
**range(start, stop, step)**生成一个整数序列。
enumerate(iterable, start=0) 返回枚举对象,生成 (index, value) 对。
**zip(\*iterables)**将多个可迭代对象组合成一个元组序列。
**sorted(iterable, key=None, reverse=False)**返回排序后的列表。
**reversed(sequence)**返回反转后的迭代器。
**all(iterable)**如果可迭代对象中的所有元素为真,则返回 True。
**any(iterable)**如果可迭代对象中的任一元素为真,则返回 True。
对象操作
**type(object)**返回对象的类型。
**isinstance(object, classinfo)**检查对象是否是指定类型的实例。
**id(object)**返回对象的唯一标识符(内存地址)。
**hash(object)**返回对象的哈希值。
**help(object)**查看对象的帮助信息。
**dir(object)**返回对象的属性和方法列表。
函数操作
- **
map(function, iterable, ...)**将函数应用于可迭代对象的每个元素。 - **
filter(function, iterable)**过滤可迭代对象中满足条件的元素。 - **
reduce(function, iterable, initializer=None)**对可迭代对象进行累积计算(需从functools导入)。 - **
lambda**创建匿名函数。
文件操作
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None) 打开文件并返回文件对象。
其他常用函数
- **
eval(expression, globals=None, locals=None)**执行字符串形式的表达式并返回结果。 - **
exec(object, globals=None, locals=None)**执行字符串形式的代码。 - **
globals()**返回当前全局符号表。 - **
locals()**返回当前局部符号表。 - **
chr(i)**返回 Unicode 码点为i的字符。 - **
ord(c)**返回字符c的 Unicode 码点。 - **
bin(x)**将整数转换为二进制字符串。 - **
hex(x)**将整数转换为十六进制字符串。 - **
oct(x)**将整数转换为八进制字符串。
异常
异常的处理机制
try-excepttry-except-except-...-except- 捕获顺序:先子类后父类(由小到大)
BaseException是最大的异常
try-except-else- 没遇到异常就执行else
try-except-else-finally- finally:无论是否遇到异常都会执行
python常见的异常类型
ZeroDivisionError:除(或取模)零IndexError:序列中没有此索引KeyError:映射中没有这个键NameError:未声明/初始化对象(没有属性)SyntaxError:语法错误ValueError:传入无效参数
traceback模块
# try-except
try:
n1=int(input("请输入第一个数:"))
n2=int(input("请输入第二个数:"))
res=n1/n2
print('结果为:{0:0.2}'.format(res))
except ZeroDivisionError:
print("除数不能为0")
print("程序结束")
请输入第一个数:1
请输入第二个数:0
除数不能为0
程序结束
# try-except-except-...-except
try:
n1=int(input("请输入第一个数:"))
n2=int(input("请输入第二个数:"))
res=n1/n2
print('结果为:{0:0.2}'.format(res))
except ZeroDivisionError:
print("除数不能为0")
except ValueError:
print("您输入的不是数字")
except BaseException as e:# BaseException
print(e)
print("程序结束")
请输入第一个数:-
您输入的不是数字
程序结束
# try-except-else
try:
n1=int(input("请输入第一个数:"))
n2=int(input("请输入第二个数:"))
res=n1/n2
except ZeroDivisionError:
print("除数不能为0")
except ValueError:
print("您输入的不是数字")
except BaseException as e:# BaseException
print(e)
else:
print('结果为:{0:0.2}'.format(res))
print("程序结束")
请输入第一个数:1
请输入第二个数:2
结果为:0.5
程序结束
# try-except-else-finally
try:
n1=int(input("请输入第一个数:"))
n2=int(input("请输入第二个数:"))
res=n1/n2
except ZeroDivisionError:
print("除数不能为0")
except ValueError:
print("您输入的不是数字")
except BaseException as e:# BaseException
print(e)
else:
print('结果为:{0:0.2}'.format(res))
finally:
print("程序结束")
请输入第一个数:-
您输入的不是数字
程序结束
import traceback
try:
print('-----1-------')
num=1/0
except: # 不写,发生异常就直接走这段代码
traceback.print_exc()
-----1-------
Traceback (most recent call last):
File "/var/folders/06/0p7d3_4x4xsgmjl7lb00hvg80000gn/T/ipykernel_3338/1999639933.py", line 4, in <module>
num=1/0
ZeroDivisionError: division by zero
对象
两大编程思想
- 面向过程
- 面向对象
类和对象的创建
数据类型与对象:
不同的数据类型属于不同的类。如100、99、520都是int类的不同实例,即对象
像int、list、dict等都是类,其具体的value就是一个个实例
类的创建
创建语法:
class Student: 属性/方法等类的组成:
- 类属性
- 实例方法
- 静态方法:
@staticmethod - 类方法:
@classmethod - 初始化方法:
__init__
对象的创建
- 对象的创建又称类的实例化
- 语法:
实例名=类名()
# 创建类
class Student:
pass
'''
当我们定义Student类的时候,也会在内存中开辟空间,Student是一个类对象
'''
print(id(Student)) # 140205459718400
print(type(Student)) # <class 'type'>
print(Student) # <class '__main__.Student'>
'''-------------------------------------类的定义-----------------------------------------'''
class Student:
#类属性
native_place='深圳'# 类里面定义的变量称为类属性
#初始化方法:用于初始化对象,类似java的构造器
def __init__(self,name,age):
'''
self.name称为实例属性,进行了一个赋值操作,将局部变量的name的值赋给实体属性
这里也可以是self.a=name,但是这样就不见名知意了
'''
self.name=name
self.age=age
# 实例方法,定义在类之后的称为函数
def eat(self):#只是习惯用self,写a也可以
print('学生吃饭')
#静态方法
@staticmethod
def smethod():
print("----静态方法-----")
#类方法
@classmethod
def claMethod(cls):#同self
print('----类方法-------')
'''----------------------------------------对象的创建和使用-----------------------------'''
# 创建对象
print('----------实例对象------------')
jack=Student('jack',20)
print(jack)
print(id(jack))# 地址值:十进制-4547494336 十六进制-0x10f0d41c0
print(type(jack))
print('----------类对象------------')
print(Student)
print(id(Student))
print(type(Student))
print('----------访问实例属性------------')
print(jack.name)#对象名.实例属性名
print(jack.age)
print('----------调用实例方法------------')
jack.eat()# 对象名.方法名
Student.eat(jack)# 类名.方法名(类的实例)-->实际上就是方法定义处的self
----------实例对象------------
<__main__.Student object at 0x10ee4f730>
4544853808
<class '__main__.Student'>
----------类对象------------
<class '__main__.Student'>
140205437441424
<class 'type'>
----------访问实例属性------------
jack
20
----------调用实例方法------------
学生吃饭
学生吃饭
类对象和类属性
类属性-类方法-静态方法的使用
- 类属性的访问:实例对象共用一个类属性
实例对象名.类属性名类名.类属性名
- 类方法:
类名.类方法名 - 静态方法:
类名.静态方法
class Student:
#类属性
native_place='深圳'# 类里面定义的变量称为类属性
#初始化方法:用于初始化对象,类似java的构造器
def __init__(self,name,age):
'''
self.name称为实例属性,进行了一个赋值操作,将局部变量的name的值赋给实体属性
这里也可以是self.a=name,但是这样就不见名知意了
'''
self.name=name
self.age=age
# 实例方法,定义在类之后的称为函数
def eat(self):#只是习惯用self,写a也可以
print('学生吃饭')
#静态方法
@staticmethod
def smethod():
print("----静态方法-----")
#类方法
@classmethod
def claMethod(cls):#同self
print('----类方法-------')
'''-------------------------------类对象-类属性-静态方法-----------------------------'''
print('--------类属性的使用---------')
print(Student.native_place) # 深圳
stu1=Student('张三',20)
stu2=Student('李四',23)
print(stu1.native_place) # 深圳
print(stu2.native_place) # 深圳
Student.native_place='广州'
print(stu1.native_place) # 广州
print(stu2.native_place) # 广州
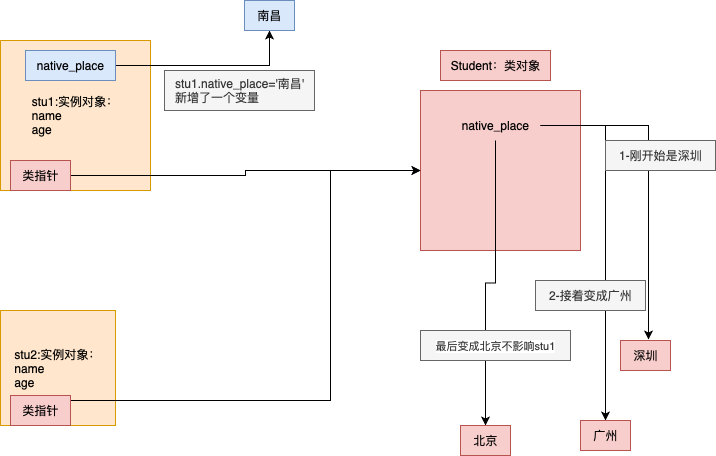
'''
stu1和sut2共用native_place这个类属性
但是stu1.native_place='南昌'这个操作,相当于往stu1这个实例对象里面动态绑定了一个native_place的实例属性
于是stu1.native_place优先会访问实例对象的native_place属性
'''
stu1.native_place='南昌'
print(stu1.native_place)# 只改了stu1的值 # 南昌
print(stu2.native_place) # 广州
Student.native_place='北京'
print(stu1.native_place)# stu1回不去了 # 南昌
print(stu2.native_place) # 北京
print('--------类方法的使用---------')
Student.claMethod()#类方法有默认参数
print('--------静态方法的使用---------')
Student.smethod()#静态方法没有默认参数
--------类属性的使用---------
深圳
深圳
深圳
广州
广州
南昌
广州
南昌
北京
--------类方法的使用---------
----类方法-------
--------静态方法的使用---------
----静态方法-----
类属性的内存分析
静态方法与类方法的区别
| 特性 | 静态方法(Static Method) | 类方法(Class Method) |
|---|---|---|
| 装饰器 | @staticmethod |
@classmethod |
| 参数 | 无 self 或 cls 参数 |
第一个参数是 cls(表示类本身) |
| 访问类属性 | 不能访问类属性 | 可以访问类属性 |
| 访问实例属性 | 不能访问实例属性 | 不能访问实例属性 |
| 用途 | 与类相关但不依赖类或实例的功能 | 操作类属性或创建工厂方法 |
| 调用方式 | 通过类或实例调用 | 通过类或实例调用 |
# 静态方法
class StringUtils:
@staticmethod
def is_palindrome(s):
return s == s[::-1]
# 调用静态方法
print(StringUtils.is_palindrome("racecar")) # 输出: True
class Person:
min_age = 18
def __init__(self, name, age):
self.name = name
self.age = age
@classmethod
def create_adult(cls, name):
return cls(name, cls.min_age)
# 调用类方法
adult = Person.create_adult("Alice")
print(adult.name, adult.age) # 输出: Alice 18
动态绑定属性和方法
动态绑定属性和方法的内存分析图
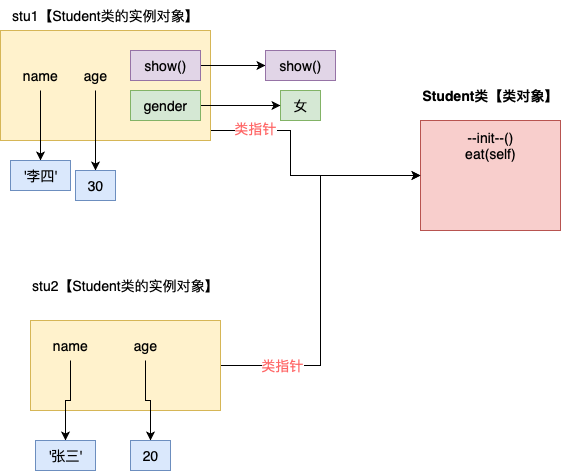
# 绑定动态
stu1=Student('李四',30)
stu2=Student('张三',20)
#绑定属性
stu1.gender='女'
print(stu1.name,stu1.age,stu1.gender)
#stu2没有gender属性,访问了会报错
#AttributeError: 'Student' object has no attribute 'gender'
#print(stu2.name,stu2.age,stu2.gender)
def show():
print('-----show-----')
#绑定方法
stu1.show=show
stu1.show()
#stu2没有show方法,调用会报错
#AttributeError: 'Student' object has no attribute 'show'
#stu2.show()
李四 30 女
-----show-----
对象的三大特性——封装
封装的核心思想
- 隐藏实现细节:将类的内部实现细节隐藏起来,只暴露必要的接口供外部使用。
- 保护数据:通过访问控制机制,防止外部代码直接修改类的内部数据。
- 简化使用:外部代码只需要知道类的接口(方法),而不需要了解内部的具体实现。
Python 如何实现封装
访问控制
- Python 使用命名约定来实现访问控制,而不是严格的访问修饰符(如 Java 中的
private和public)。 - 单下划线
_:- 以单下划线开头的属性和方法被视为“受保护的”(protected),表示它们仅供内部使用,但外部仍然可以访问。
- 例如:
_name。
- 双下划线
__:- 以双下划线开头的属性和方法被视为“私有的”(private),Python 会对它们进行名称修饰(name mangling),使得外部无法直接访问。
- 例如:
__name会被修饰为_ClassName__name。
class Student:
def __init__(self, name, age):
self._name = name # name这个属性外部还是可以访问,加一个 _ 的目的,是告诉开发者,这个是私有的,不要改但
self.__age = age # age不希望在类的外部被使用,所以加了两个_
def show(self):
print(self._name, self.__age)
stu = Student('jerry', 20)
stu.show()
print(stu._name)
# 直接访问__age会报错
# AttributeError: 'Student' object has no attribute '__age'
# print(stu.__age)
print('stu的属性和方法有:', dir(stu))
# stu里面有'name', 'show'还有一个'_Student__age',通过这个可以去访问
# 实际上,是Python对 __age这个变量的名字改成了_Student__age
print(stu._Student__age)
jerry 20
jerry
stu的属性和方法有: ['_Student__age', '__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'name', 'show']
20
属性访问器
- Python 提供了
@property装饰器,用于将方法转换为属性,从而控制对属性的访问。 - 通过
@property、@属性名.setter和@属性名.deleter,可以实现对属性的读取、修改和删除操作的控制
class User:
def __init__(self, user_id, name, email):
self._user_id = user_id
self._name = name
self._email=email # 使用 setter 方法设置邮箱
# Getter 方法
@property
def user_id(self):
return self._user_id
@property
def name(self):
return self._name
@property
def email(self):
return self._email
# Setter 方法
@name.setter
def name(self, name):
if not name:
raise ValueError("Name cannot be empty")
self._name = name
@email.setter
def email(self, email):
if not self._is_valid_email(email):
raise ValueError("Invalid email format")
self._email = email
# 邮箱格式校验方法
def _is_valid_email(self, email):
# 简单的邮箱格式校验
return "@" in email and "." in email.split("@")[1]
# 创建用户对象
user = User(1, "Alice", "alice@example.com")
print(user.email) # 输出: alice@example.com
try:
# 尝试设置非法邮箱
user.email="invalid-email" # 报错: ValueError
except ValueError as e:
print(e) # 输出: Invalid email format
# 修改邮箱
user.email="bob@example.com"
print(user.email) # 输出: bob@example.com
# 修改姓名
user.name = "Bob"
print(user.name) # 输出: Bob
# 尝试设置非法姓名
try:
user.name = "" # 报错: ValueError
except ValueError as e:
print(e) # 输出: Name cannot be empty
私有方法
在 Python 中,私有方法通过 双下划线 __ 作为方法名的前缀来定义。例如:
作用一:隐藏复杂逻辑
class Calculator:
def __init__(self, a, b):
self.a = a
self.b = b
# 私有方法:实现复杂的加法逻辑
def __add(self):
return self.a + self.b
# 公有方法:对外提供加法功能
def add(self):
return self.__add()
# 使用 Calculator 类
calc = Calculator(3, 5)
print(calc.add()) # 输出: 8
# 尝试调用私有方法(会报错)
# print(calc.__add()) # 报错: AttributeError
作用二:数据校验
class User:
def __init__(self, name, age):
self.name = name
self.age = age
# 私有方法:校验年龄是否合法
def __validate_age(self):
if self.age < 0 or self.age > 120:
raise ValueError("Invalid age")
# 公有方法:对外提供年龄校验功能
def validate(self):
self.__validate_age()
return "Age is valid"
# 使用 User 类
user = User("Alice", 25)
print(user.validate()) # 输出: Age is valid
# 尝试设置非法年龄
user.age = -1
# print(user.validate()) # 报错: ValueError
私有方法的访问
虽然私有方法不能被外部代码直接调用,但 Python 并没有严格的访问控制机制。通过名称修饰(name mangling),仍然可以访问私有方法。
- Python 会对私有方法的名称进行修饰,将其转换为
_类名__方法名的形式。 - 例如,
__private_method会被修饰为_MyClass__private_method。
class MyClass:
def __private_method(self):
return "Private method called"
# 创建对象
obj = MyClass()
# 通过名称修饰访问私有方法
print(obj._MyClass__private_method()) # 输出: Private method called
对象的三大特性——继承
- 语法:
class 子类(要继承的父类): - 如果一个类没有继承任何类,则默认继承object,即所有类都继承了object
- python支持多继承:class 子类(父类1,父类2)
- 定义子类时,必须在其构造函数中调用父类的构造函数
- 子类可以使用父类的属性和方法
方法重写
- 如果子类对继承自父类的某个属性或方法不满意,可以在其子类中对其(方法体)进行重新编写
- 子类重写后的方法中可以通过super().xxx()调用父类中的方法
class Person(object):#不写object也可以
def __init__(self,name,age):
self.name=name
self.age=age
def info(self):
print(self.name,self.age)
def eat(self):
print('----eat-----')
class Student(Person): # 表明继承了Person
def __init__(self,name,age,stu_no):
# 这个super()应该类似于java的super,返回的是父类的实例对象
super().__init__(name,age)
self.stu_no=stu_no
#重写父类方法
def info(self):
#再使用父类的info方法
super().info()
print(self.stu_no)
class Teacher(Person):
def __init__(self,name,age,teach_year):
# 这个super()应该类似于java的super,返回的是父类的实例对象
super().__init__(name,age)
self.teach_year=teach_year
#重写父类方法
def info(self):
#再使用父类的info方法
super().info()
print(self.teach_year)
#这样就是多继承
class A (Student,Teacher):
pass
stu=Student('张三',20,'1001')
tec=Teacher('李四',34,10)
stu.info()#调用重写的方法
tec.info()#调用重写的方法
stu.eat()#可以使用父类的方法
tec.eat()#可以使用父类的方法
张三 20
1001
李四 34
10
----eat-----
----eat-----
object类
- object类是所有类的父类,因此所有类都有object的属性和方法
- 内置函数
dir()可以查看知道对象所有属性 - Object有一个
__str__()方法,用于返回“对象的描述”(类似java的toString)
class Student:
def __init__(self,name,age):
self.name=name
self.age=age
def __str__(self):
return '我的名字是{0},今年{1}岁'.format(self.name,self.age)
stu=Student('jerry',20)
'''
没有重写object的__str__方法前:
print(stu)输出的是:<__main__.Student object at 0x10a88af40>
重写object的__str__方法后:
print(stu)输出的是:我的名字是jerry,今年20岁
'''
print(stu)
'''
print(stu)方法内部调用了stu的__str__()方法
'''
st=stu.__str__()
print(st,type(st))
我的名字是jerry,今年20岁
我的名字是jerry,今年20岁 <class 'str'>
对象的三大特性——多态
在java中的多态是这样的:父类的引用指向子类的对象
如:
Person person = new Student(),如果我们调用person.eat(),实际上调用的是Student(子类)的方法在Python中的多态是这样体现的:只要有同名方法就可以调用,而不需要关注对象
class Animal(object):
def eat(self):
print("Animal:eat")
class Dog(Animal):
def eat(self):
print("Dog:eat")
class Cat(Animal):
def eat(self):
print("Cat:eat")
class Person(object):
def eat(self):
print("Person:eat")
def fun(obj):
obj.eat()
fun(Cat())
fun(Dog())
'''
没有任何继承关系的也可以调用,只要方法名字相同就好
这个与其弱类型语言的特征有关
个人觉得好用,但是危险。你永远无法知道你队友的水平是怎样的
'''
fun(Person())
Cat:eat
Dog:eat
Person:eat
魔法属性
在 Python 中,魔法属性(Magic Attributes)是以双下划线 __ 开头和结尾的特殊属性。它们通常用于访问对象的元信息或控制对象的行为。以下是几个常用的魔法属性及其作用:
类相关
__class__:获取对象所属的类。__bases__: 获取类的基类(父类)元组。__name__: 获取类的名称__module__: 取类或函数所属的模块名称。
class A:
pass
class B:
pass
class C(A,B):
pass
xc=C()
print(xc.__class__) # <class '__main__.C'>
print(C.__bases__) # (<class '__main__.A'>, <class '__main__.B'>)
print(C.__name__) # C
print(C.__module__) # __main__
print(xc.__module__) # __main__
对象相关
__dict__
- 作用:获取对象或类的属性字典。
- 示例:
class MyClass: def __init__(self, x, y): self.x = x self.y = y obj = MyClass(1, 2) print(obj.__dict__) # 输出: {'x': 1, 'y': 2}
__doc__
- 作用:获取类或函数的文档字符串(docstring)。
- 示例:
class MyClass: """这是一个示例类""" pass print(MyClass.__doc__) # 输出: 这是一个示例类
__annotations__
- 作用:获取类或函数的注解(annotations)。
- 示例:
class MyClass: x: int y: str print(MyClass.__annotations__) # 输出: {'x': <class 'int'>, 'y': <class 'str'>}
模块相关
__file__
- 作用:获取模块的文件路径。
- 示例:
import os print(os.__file__) # 输出: os 模块的文件路径
__package__
- 作用:获取模块所属的包名称。
- 示例:
import os print(os.__package__) # 输出: ''(os 是标准库模块,没有包) import my_package.pkg_module print(pkg_module.__package__) # my_package
函数相关
__defaults__
- 作用:获取函数的默认参数值。
- 示例:
def my_func(a, b=2, c=3): pass print(my_func.__defaults__) # 输出: (2, 3)
__code__
- 作用:获取函数的代码对象。
- 示例:
def my_func(): pass print(my_func.__code__)#<code object my_func at 0x1014ff910, file "/Users/.../04magic.py", line 29>
__globals__
- 作用:获取函数的全局命名空间字典。
- 示例:
def my_func(): pass ''' 输出: 全局命名空间字典 {'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x10b461190>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': '/Users/.../05global.py', '__cached__': None, 'my_func': <function my_func at 0x10b3ff740>} ''' print(my_func.__globals__)
异常相关
__traceback__
- 作用:获取异常的追踪信息。
- 示例:
try: 1 / 0 except Exception as e: print(e.__traceback__) # 输出: 异常的追踪信息
__cause__
- 作用:获取异常的引发原因(如果有)。
- 示例:
try: raise ValueError("原因") from TypeError("原始异常") except ValueError as e: print(e.__cause__) # 输出: TypeError("原始异常")
魔法方法
在 Python 中,魔法方法(Magic Methods)是以双下划线 __ 开头和结尾的特殊方法。它们用于定义类的行为,例如对象的初始化、字符串表示、运算符重载等。
对象生命周期相关
__new__(cls, \*args, \**kwargs)
作用:创建对象实例,通常用于控制对象的创建过程(如单例模式)。
调用时机:在
__init__之前调用。示例:
class Singleton: _instance = None def __new__(cls, *args, **kwargs): if cls._instance is None: cls._instance = super().__new__(cls) return cls._instance obj1 = Singleton() obj2 = Singleton() print(obj1 is obj2) # 输出: True
__init__(self, ...)
- 作用:构造函数,用于初始化对象。
- 调用时机:在创建对象时自动调用。
- 示例:
class Person: def __init__(self, name, age): self.name = name self.age = age p = Person("Alice", 25) print(p.name, p.age) # 输出: Alice 25
__del__(self)
- 作用:析构函数,用于在对象被销毁时执行清理操作。
- 调用时机:在对象被垃圾回收时自动调用。
- 示例:
class Person: def __del__(self): print("对象被销毁") p = Person() del p # 输出: 对象被销毁
init-new顺序
'''
init-new顺序:先通过new方法创建对象(1568),再通过init方法对对象(1568)进行赋值
object对象(9520)--->类对象Person(3712)
--->new传入的cls(3712)-->调用父类的new方法得到的obj对象(1568)
--->init的self(1568)
--->最后的实例对象(1568)
p1=Person('张三',20):把Person(3712)传给了__new__的cls
obj=super().__new__(cls):把Person传给了object的__new__方法,创建对象obj(1568)
return obj:返回给__init__的self(1568)
self初始化完成之后又给了p1(1568)
'''
class Person(object):
def __init__(self,name,age):
print('__init__被调用了,self的id值为{0}'.format(id(self)))
self.name=name
self.age=age
def __new__(cls,*args,**kwargs):
print('__new__被调用执行了,cls的id值为{0}'.format(id(cls)))
obj=super().__new__(cls)
print('创建的对象的id为:{0}'.format(id(obj)))
return obj
print('object这个类对象的id为:{0}'.format(id(object)))
print('Person这个类对象的id为:{0}'.format(id(Person)))
p1=Person('张三',20)
print('p1这个Person类的实例对象的id:{0}'.format(id(p1)))
object这个类对象的id为:4411189520
Person这个类对象的id为:140462607923712
__new__被调用执行了,cls的id值为140462607923712
创建的对象的id为:4469041568
__init__被调用了,self的id值为4469041568
p1这个Person类的实例对象的id:4469041568
字符串表示相关
__str__(self)
作用:定义对象的字符串表示,用于
print()和str()。调用时机:当调用
print(obj)或str(obj)时自动调用。示例:
class Person: def __init__(self, name, age): self.name = name self.age = age def __str__(self): return f"Person(name={self.name}, age={self.age})" p = Person("Alice", 25) print(p) # 输出: Person(name=Alice, age=25)
__repr__(self)
作用:定义对象的“官方”字符串表示,用于调试和开发。
调用时机:当调用
repr(obj)或在交互式环境中直接输入对象时自动调用。示例:
class Person: def __init__(self, name, age): self.name = name self.age = age def __repr__(self): return f"Person(name={self.name}, age={self.age})" p = Person("Alice", 25) print(repr(p)) # 输出: Person(name=Alice, age=25)
运算符重载相关
__add__(self, other)
- 作用:定义
+运算符的行为。 - 调用时机:当使用
obj1 + obj2时自动调用。 - 示例:
class Point: def __init__(self, x, y): self.x = x self.y = y def __add__(self, other): return Point(self.x + other.x, self.y + other.y) def __str__(self): return f"Point({self.x}, {self.y})" p1 = Point(1, 2) p2 = Point(3, 4) print(p1 + p2) # 输出: Point(4, 6)
__eq__(self, other)
- 作用:定义
==运算符的行为。 - 调用时机:当使用
obj1 == obj2时自动调用。 - 示例:
class Point: def __init__(self, x, y): self.x = x self.y = y def __eq__(self, other): return self.x == other.x and self.y == other.y p1 = Point(1, 2) p2 = Point(1, 2) print(p1 == p2) # 输出: True
容器相关
__len__(self)
- 作用:定义对象的长度,用于
len()。 - 调用时机:当调用
len(obj)时自动调用。 - 示例:
class MyList: def __init__(self, items): self.items = items def __len__(self): return len(self.items) ml = MyList([1, 2, 3]) print(len(ml)) # 输出: 3
__getitem__(self, key)
- 作用:定义通过索引访问元素的行为,用于
obj[key]。 - 调用时机:当使用
obj[key]时自动调用。 - 示例:
class MyList: def __init__(self, items): self.items = items def __getitem__(self, index): return self.items[index] ml = MyList([1, 2, 3]) print(ml[1]) # 输出: 2
__setitem__(self, key, value)
- 作用:定义通过索引设置元素的行为,用于
obj[key] = value。 - 调用时机:当使用
obj[key] = value时自动调用。 - 示例:
class MyList: def __init__(self, items): self.items = items def __setitem__(self, index, value): self.items[index] = value ml = MyList([1, 2, 3]) ml[1] = 99 print(ml.items) # 输出: [1, 99, 3]
上下文管理相关
__enter__(self)
- 作用:定义进入上下文时的行为,用于
with语句。 - 调用时机:当进入
with语句块时自动调用。 - 示例:
class MyContext: def __enter__(self): print("进入上下文") return self def __exit__(self, exc_type, exc_val, exc_tb): print("退出上下文") with MyContext() as mc: print("在上下文中") # 输出: # 进入上下文 # 在上下文中 # 退出上下文
__exit__(self, exc_type, exc_val, exc_tb)
- 作用:定义退出上下文时的行为,用于
with语句。 - 调用时机:当退出
with语句块时自动调用。 - 参数:
exc_type:异常类型。exc_val:异常值。exc_tb:异常追踪信息。
类的浅拷贝与深拷贝
- 变量的赋值操作:只是形成两个变量,实际上还是指向同一个对象
- 浅拷贝:python拷贝一般都是浅拷贝,拷贝时,对象包含的子对象内容不拷贝,因此,源对象与拷贝对象会引用同一个子对象
- 深拷贝: 使用copy模块的deepcopy函数,递归拷贝对象中包含的子对象,源对象和拷贝对象所有的子对象也不相同
class CPU:
pass
class Disk:
pass
class Computer:
def __init__(self,cpu,disk):
self.cpu=cpu
self.disk=disk
print('''-----------------赋值操作------------------------''')
cpu1=CPU()
cpu2=cpu1
print(cpu1)#0x10a941700 同一个内存地址
print(cpu2)#0x10a941700 同一个内存地址
print('''-----------------浅拷贝操作------------------------''')
import copy
disk=Disk()
computer=Computer(cpu1,disk)
'''
computer1和computer2是两个不同的对象,有不同的地址值
但里面的 子对象(CPU) 是相同的有相同的地址值
'''
computer2=copy.copy(computer)
print(computer,computer.cpu,computer.disk)
print(computer2,computer2.cpu,computer2.disk)
print('''-----------------深拷贝操作------------------------''')
'''
深拷贝的子对象的地址都不相同,深拷贝会再产生内存空间来存储子对象
'''
computer3=copy.deepcopy(computer)
print(computer,computer.cpu,computer.disk)
print(computer3,computer3.cpu,computer3.disk)
-----------------赋值操作------------------------
<__main__.CPU object at 0x10a941700>
<__main__.CPU object at 0x10a941700>
-----------------浅拷贝操作------------------------
<__main__.Computer object at 0x10a888430> <__main__.CPU object at 0x10a941700> <__main__.Disk object at 0x10a941c70>
<__main__.Computer object at 0x10a941b20> <__main__.CPU object at 0x10a941700> <__main__.Disk object at 0x10a941c70>
-----------------深拷贝操作------------------------
<__main__.Computer object at 0x10a888430> <__main__.CPU object at 0x10a941700> <__main__.Disk object at 0x10a941c70>
<__main__.Computer object at 0x10a941dc0> <__main__.CPU object at 0x10a8b1910> <__main__.Disk object at 0x10a8b1640>
对象复制 的魔法方法
__copy__(self)
作用:定义对象的浅拷贝行为,用于
copy.copy()。调用时机:当调用
copy.copy(obj)时自动调用。示例:
import copy class MyClass: def __init__(self, value): self.value = value def __copy__(self): return MyClass(self.value) obj1 = MyClass(10) obj2 = copy.copy(obj1) print(obj2.value) # 输出: 10
__deepcopy__(self, memo)
作用:定义对象的深拷贝行为,用于
copy.deepcopy()。调用时机:当调用
copy.deepcopy(obj)时自动调用。示例:
import copy class MyClass: def __init__(self, value): self.value = value def __deepcopy__(self, memo): return MyClass(copy.deepcopy(self.value, memo)) obj1 = MyClass([1, 2, 3]) obj2 = copy.deepcopy(obj1) print(obj2.value) # 输出: [1, 2, 3]
模块
模块的导入与使用
什么叫模块
- 模块 就好比是 工具包,要想使用这个工具包中的工具,就需要 导入 import 这个模块
- 每一个以扩展名
py结尾的 python 源代码文件都是一个 模块 - 在模块中定义的 全局变量 、 函数 都是模块能够提供给外界直接使用的工具
自定义模块
- 创建模块:新建一个
.py文件,名称尽量不用与Python自带的标准模块名称相同 - 导入模块
import 模块名称 as 别名from 模块名称 import 函数/变量/类
- 导入的模块也是一个对象,有内存地址,类型(module)等
- 创建模块:新建一个
import 模块名称
import my_module
my_module.print_my_module()
print(my_module.my_modele_value)
import 模块名称 as 别名
import my_module as mu
mu.print_my_module()
print(mu.my_modele_value)
from 模块名称 import 函数/变量/类
from my_module import print_my_module,my_modele_value
print_my_module()
print(my_modele_value)
from 模块名称 import *
from my_module import *
print_my_module()
print(my_modele_value)
以主程序的形式执行 :
创建my_module_2.py文件,文件内容如下
# 代码A
print("这是代码A,无论模块是被导入还是直接运行,都会执行")
# 代码B
if __name__ == '__main__':
print("这是代码B,只有模块被直接运行时才会执行")
如果单独执行my_module_2.py文件,会打印如下两句话:
这是代码A,无论模块是被导入还是直接运行,都会执行
这是代码B,只有模块被直接运行时才会执行
创建test05.py文件,导入my_module_2.py
import my_module_2
print("test05 run")
执行test05.py,有如下结果:代码B没有执行
这是代码A,无论模块是被导入还是直接运行,都会执行
test05 run
以上module都是在引入文件的同一级目录,如果想尝试其他目录,需要使用包
包的使用
- python中的包
包是一个分层次的目录结构,它将一组功能相近的模块组织在一个目录下
包的作用
- 代码规范
- 避免模块名称冲突
包的导入:
import 包名.模块名 as 别名from 包名 import 模块名from 包名.模块名 import 函数/变量/类
目录与包
包在pycharm中是Python Package,会有一个
__init__的py文件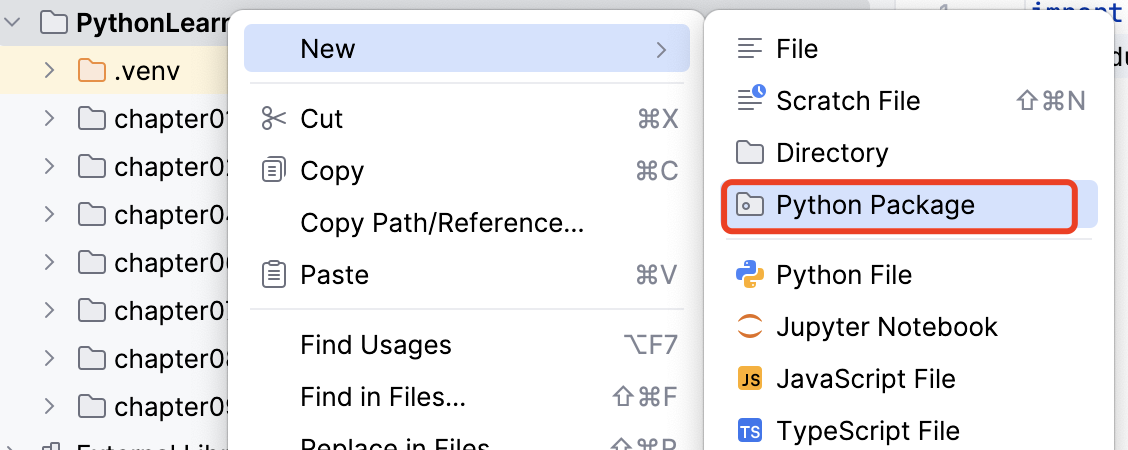
目录是Directory,没有init文件
# import my_package.pkg_module as pkg
from my_package import pkg_module as pkg
pkg.print_pkg()
常见的标准库
- sys:与Python解释器及其环境操作相关的标准库
- time:提高与时间相关的各种函数的标准库
- os:提供访问操作系统服务功能的标准库
- calendar:提供与日期相关的各种函数的标准库
- urllib:用于读取来自网上(服务器)的数据标准库
- json:用于石油Json序列化和反序列化对象
- re:用于在字符串中执行正则表达式匹配和替换
- math:提供标准算术运算函数的标准库
- decimal:用于进行精确控制运算精度、有效位数和四舍五入的十进制运算
- logging:提供了灵活的记录事件、错误、警告和调试信息等日子信息等功能
random 库
import random
# random() 返回一个[0.0,1.0)之间的随机小数
a = random.random()
print("random.random()=",a)
# randrange(start,stop,step)
# start 指定范围的起始值 包含本身,默认是0;
# stop 指定范围的结束值 不包含本身;
# step 步长,默认步长是1。该函数返回一个整数
print("random.randrange(1,10,2)=",random.randrange(1,10,2))
# randint(start,end) 返回[start end]之间的一个随机整数,start必须小于end
a = random.randint(1,200)
print("random.randint(1,200)=",a)
# 获取列表中的随机元素
list1 = [1,2,3,4,5,6]
# choice(seq) 从非空序列(如列表、元组、字符串等)中随机选择一个元素
print("random.choice(list1)=",random.choice(list1))
print("random.choice('hello')=",random.choice('hello'))
# shuffle(seq) 用于随机打乱序列(如列表)中元素的顺序。
# 注意,shuffle() 会直接修改原序列,而不是返回一个新的打乱顺序的序列
# - seq:需要打乱顺序的序列(通常是列表)。
# - 无返回值(None),直接修改原序列。
# 只能用于可变序列:shuffle() 会直接修改原序列,因此只能用于可变序列(如列表)。
# 如果需要打乱不可变序列(如元组、字符串),可以先将序列转换为列表,打乱后再转换回去。
random.shuffle(list1)
print("random.shuffle(list1)=",list1) # [6, 5, 4, 2, 1, 3]
math 库
import math
# math.ceil() 向上取整
print(math.ceil(3.14),math.ceil(3.51)) # 4 4
# math.floor() 向下取整
print(math.floor(3.14),math.floor(3.51)) # 3 3
# round 是内置函数:四舍五入
print(round(3.14),round(3.51)) # 3 4
# math.sqrt 求平方根
print(math.sqrt(5)) # 2.23606797749979
re库:正则表达式
import re
# \d:匹配任意数字(等价于 [0-9])。
# \D:匹配任意非数字字符(等价于 [^0-9])。
# +:匹配前面的字符 1 次或多次
# 检测字符串是否为纯数字的字符串
result = re.match(r'\d+','1234234234')
print(result) # <re.Match object; span=(0, 10), match='1234234234'>
# \w:匹配任意字母、数字或下划线(等价于 [a-zA-Z0-9_])。
# \W:匹配任意非字母、数字或下划线的字符(等价于 [^a-zA-Z0-9_])。
result = re.match(r'\w+','a*8')
print(result) # <re.Match object; span=(0, 1), match='a'>
# ^:匹配字符串的开头。
# $:匹配字符串的结尾
# \s:匹配任意空白字符(包括空格、制表符、换行符等)。
# \S:匹配任意非空白字符。
# ^\s+$ 匹配一个完全由空白字符组成的字符串。
result= re.match(r'^\s+$',' f ')
print(result) # None
# . 匹配除换行符以外的任意字符。
result = re.match(r'^code\d-\d-.+$','code5-2-random')
print(result) # <re.Match object; span=(0, 14), match='code5-2-random'>
# []区间,可选列表
# [abc]:匹配 a、b 或 c 中的任意一个字符。
# [^abc]:匹配除 a、b、c 以外的任意字符。
# [a-z]:匹配任意小写字母。
# [A-Z]:匹配任意大写字母。
# [0-9]:匹配任意数字。
# {n}:匹配前面的字符恰好 n 次。
# {n,}:匹配前面的字符至少 n 次。
# {n,m}:匹配前面的字符至少 n 次,至多 m 次。
# 正则表达式 ^abc{2,5} 的含义是:匹配以 ab 开头,后跟 2 到 5 个 c 的字符串。
result = re.match(r'^abc{2,5}$','abccc')
print(result) # <re.Match object; span=(0, 5), match='abccc'>
# | 或者
# |:匹配左边或右边的模式。 示例:a|b 匹配 a 或 b。
result = re.match(r'^a|b|c$','d')
print(result) # None
# 身份证号
# ^\d{6}:匹配前 6 位数字。
"""
((20[012][01234])|(1[89]\d\d)):匹配年份部分。
这是一个分组,包含两个分支:
20[012][01234]:
20:匹配字符 20。
[012]:匹配 0、1 或 2。
[01234]:匹配 0、1、2、3 或 4。
含义:匹配年份范围 2000 到 2024。
1[89]\d\d:
1:匹配字符 1。
[89]:匹配 8 或 9。
\d\d:匹配任意两位数字。
含义:匹配年份范围 1800 到 1999。
整体含义:匹配年份范围 1800 到 1999 或 2000 到 2024。
"""
# \d{7}:匹配接下来的 7 位数字。
# ([\dX])$:匹配最后一位(数字或字母 X)
result = re.match(r'^\d{6}((20[012][01234])|(1[89]\d\d))\d{7}([\dX])$','12345619951234567X')
print(result) # <re.Match object; span=(0, 18), match='12345619951234567X'>
result = re.match(r'^20[012][01234]$','2008')
print(result)
result = re.match(r'^1[89]\d\d$','1998')
print(result)
# 手机号码
result =re.match(r'^1\d{10}$','12345678391')
print(result)
time 库
import time
t = time.time() # 时间戳:1970年
print(t) # 1741443622.177233
t = time.localtime() # 结构化的时间
# time.struct_time(tm_year=2025, tm_mon=3, tm_mday=8, tm_hour=22, tm_min=20, tm_sec=22, tm_wday=5, tm_yday=67, tm_isdst=0)
print(t)
print(t.tm_year,type(t.tm_year)) # 获取 # 2025 <class 'int'>
s = time.strftime('%Y-%m-%d %H:%M:%S',t)
print(s) # 2025-03-08 22:20:22
turtle库
Turtle : 1969年诞生,Python语言的标准库之一,入门级的图形绘制函数库
| 方法 | 说明 |
|---|---|
| forward(d)/fd(d) | 向当前画笔方向移动d像素长度 |
| backward(d)/back(d)/bk(d) | 向当前画笔相反方向移动d像素长度 |
| goto(x,y)/setpos(x,y)/setposition(x,y) | 将画笔移动到坐标为x,y的位置 |
| setx(x) | 设置海龟的横坐标为 x,纵坐标保持不变 |
| sety(y) | 设置海龟的纵坐标为 y,横坐标保持不变 |
| penup()/up() | 提起笔移动,不绘制图形,用于另起一个地方绘制 |
| pendown()/down() | 放下笔,移动时绘制图形,缺省时也为绘制 |
| right(degree)/rt(degree) | 顺时针移动degree° |
| left(degree)/lt(degree) | 逆时针移动degree° |
| setheading(angle)/seth(angle) | 设置海龟的朝向为 angle |
| circle(radius, extent=None, steps=None) | 绘制圆弧 |
| dot(radius,colorstr) | 绘制一个指定直径和颜色的圆点 |
| home() | 设置当前画笔位置为原点,朝向东 |
import turtle
pen = turtle.Turtle()
pen.forward(100)
for i in range(100):
pen.right(85)
pen.forward(100)
import turtle
import time
pen = turtle.Turtle()
pen.color('green')
while(True):
pen.clear()
localtime = time.localtime()
strftime = time.strftime("%Y-%m-%d %H:%M:%S", localtime)
pen.write(strftime,font=("Arial",30,"bold"),align="center")
time.sleep(1)
socket 库
以下是一个简单的网络通信:
server
import socket
# 创建socket对象
# 默认情况下,socket.socket() 创建的是 TCP socket(socket.SOCK_STREAM)
sk = socket.socket()
# 绑定ip和端口号:将 socket 绑定到 IP 地址 0.0.0.0 和端口 8995。
sk.bind(("0.0.0.0",8995))
# 设置监听: 将 socket 设置为监听模式,等待客户端连接。
# 参数 5 表示最大连接队列长度(即最多允许 5 个客户端等待连接)。
sk.listen(5)
# accept() 是一个阻塞方法,等待客户端连接。
# 当有客户端连接时,返回一个新的 socket 对象 conn 和客户端的地址 addr。
# conn 用于与客户端通信。
# addr 是一个元组,包含客户端的 IP 地址和端口号。
conn,addr = sk.accept()
# <socket.socket fd=4, family=2, type=1, proto=0, laddr=('127.0.0.1', 8995), raddr=('127.0.0.1', 59570)>
print(conn)
# ('127.0.0.1', 59570)
print(addr)
while True:
# conn.recv(1024) 从客户端接收数据,最多接收 1024 字节。
# 返回的数据是字节类型(bytes),需要使用 decode('utf8') 解码为字符串
accept_data = conn.recv(1024)
print('server-收到客户端发送的消息:',accept_data.decode('utf8'))
send_data = '收到!'
# 向客户端发送数据,发送前需要将字符串编码为字节类型(encode('utf8'))
conn.send(send_data.encode('utf8'))
控制台:
<socket.socket fd=4, family=2, type=1, proto=0, laddr=('127.0.0.1', 8995), raddr=('127.0.0.1', 59570)>
('127.0.0.1', 59570)
server-收到客户端发送的消息: 你好
server-收到客户端发送的消息: 你好啊啊啊啊
cline
import socket
# 创建socket对象
sk = socket.socket()
# 连接服务器
# 使用 connect() 方法连接到服务器的 IP 地址 127.0.0.1 和端口 8995。
sk.connect(("127.0.0.1",8995))
while True:
send_data = input('cline-请输入你要发送的内容:')
# 发送数据到服务器
# 将用户输入的数据编码为字节类型(encode('utf8')),并发送到服务器。
sk.send(send_data.encode('utf8'))
# 等待服务器的响应
# sk.recv(1024):
# 从服务器接收数据,最多接收 1024 字节。
# 返回的数据是字节类型(bytes),需要使用 decode('utf8') 解码为字符串。
accept_data = sk.recv(1024)
# 打印服务器的响应
print('cline-接收到服务器的响应:',accept_data.decode('utf8'))
控制台
cline-请输入你要发送的内容:你好
cline-接收到服务器的响应: 收到!
cline-请输入你要发送的内容:你好啊啊啊啊
cline-接收到服务器的响应: 收到!
第三方库
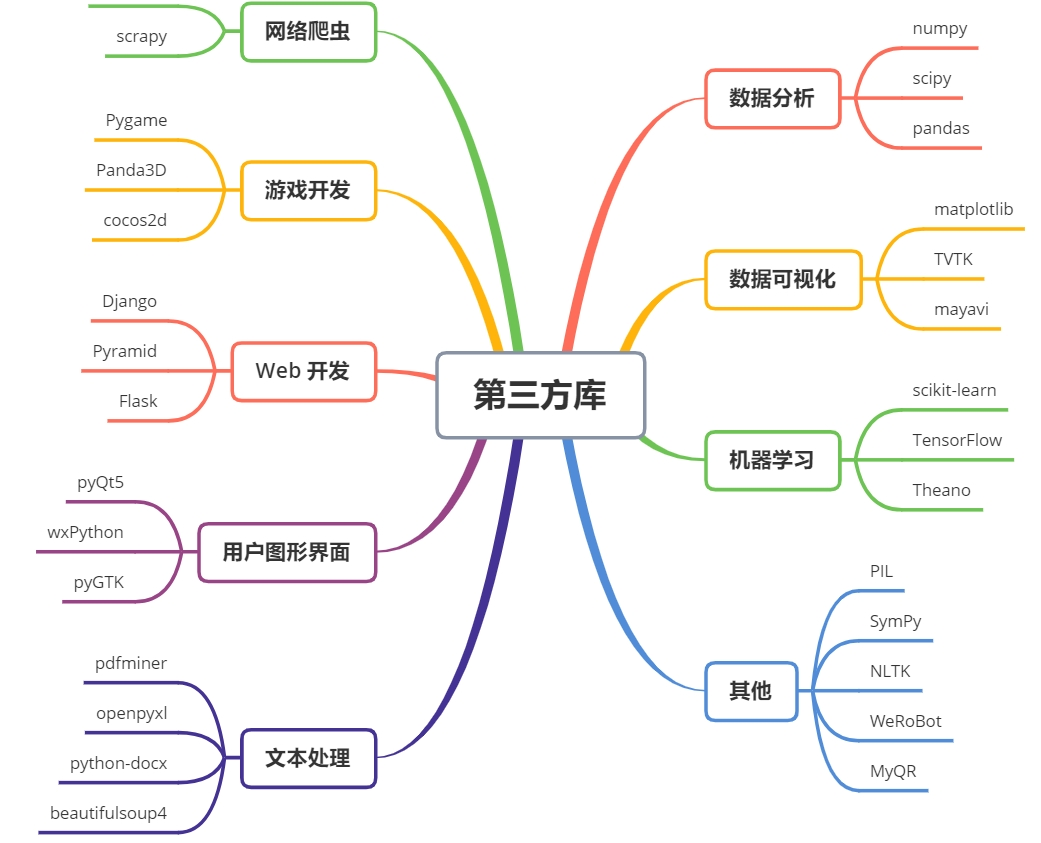
找到pycharm控制台,通过pip命令安装第三方库
pip list: 查看安装哪些库
(.venv) xieshaolin@xieshaolindeMacBook-Pro PythonLearning % pip list
Package Version
------- -------
pip 23.2.1
[notice] A new release of pip is available: 23.2.1 -> 25.0.1
[notice] To update, run: pip install --upgrade pip
pip install --upgrade pip: 更新相关库
(.venv) xieshaolin@xieshaolindeMacBook-Pro PythonLearning % pip install --upgrade pip
Requirement already satisfied: pip in ./.venv/lib/python3.13/site-packages (23.2.1)
Collecting pip
Obtaining dependency information for pip from https://files.pythonhosted.org/packages/c9/bc/b7db44f5f39f9d0494071bddae6880eb645970366d0a200022a1a93d57f5/pip-25.0.1-py3-none-any.whl.metadata
Downloading pip-25.0.1-py3-none-any.whl.metadata (3.7 kB)
Downloading pip-25.0.1-py3-none-any.whl (1.8 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.8/1.8 MB 994.6 kB/s eta 0:00:00
Installing collected packages: pip
Attempting uninstall: pip
Found existing installation: pip 23.2.1
Uninstalling pip-23.2.1:
Successfully uninstalled pip-23.2.1
Successfully installed pip-25.0.1
更新后,.venv/lib/python3.13/site-packages 这个文件夹会有变化
设置镜像:pip config set global.index-url https://mirrors.aliyun.com/pypi/simple
安装第三方库:pip install scrapy
卸载第三方库:pip uninstall scrapy
文件
什么是文件
文件是以计算机硬盘为载体存储在计算机上的信息集合,文件可以是文本文档、图片、程序等等。计算机文件基本上分为二种:二进制文件(没有统一的字符编码)和纯文本文件(有统一的编码,可以被看做存储在磁盘上的长字符串)。
纯文本文件编码格式常见的有 ASCII、ISO-8859-1、GB2312、GBK、UTF-8、UTF-16 等。
二进制文件与文本文件的一个最主要的区别在于是否有统一的字符编码格式,二进制文件顾名思义是直接由0与1组成,无统一的字符编码。如图片文件(jpg、png),视频文件(avi)等。
编码格式
python的解释器使用的是Unicode(内存)
.py文件在磁盘上使用UTF-8存储(外存)
常见编码格式:
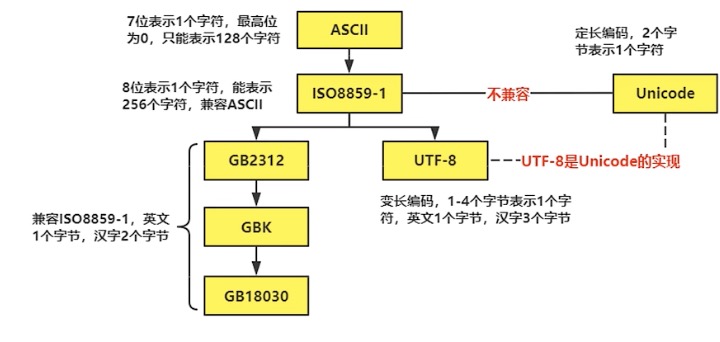
文件的读写原理
- 文件的读写俗称IO操作
- 文件的读写流程
Python操作文件->打开或者新建文件->读写文件->关闭资源 - 操作原理:解释器运行.py文件,调用操作系统,操作硬盘上的文件
文件读写操作
- 文件类型:
- 文本文件:存储的是普通‘字符’文本,默认为unicode字符集,可以使用记事本程序打开
- 二进制文件:把数据内容用‘字节’进行存储,如图片,视频,音频和doc等文件
- 内置函数open创建或者打开文件:
file=open(filename,[mode,encoding])- file:被创建的文件对象
- open:创建文件对象的函数
- 要创建或打开的文件名称
- 打开模式,默认只读
- 默认文本文件中字符的编写格式文gbk
- 常用的文件打开模式
r:只读模式,文件指针放在文件的开头w:只写模式,如果文件不存在则创建,如果文件存在则覆盖原有内容,文件指针在文件开头a:追加模式,如果文件不存在则创建,文件指针在文件开头,如果文件存在则在文件末尾追加内容,文件指针在文件末尾+:以读写方式打开文件,不能单独使用,需要与其他模式一起使用a+:打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。r+:可读可写w+:打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
b:二进制模式,不能单独使用,要和其他模式一起使用。rb、wb、ab、rb+、wb+、ab+意义和上面一样,用于二进制文件操作
# 文件写入
file=open('a.txt','w')
file.write('Python')
file.close()
与read相关的方法:
read(size=-1):从文件中读取指定数量的字符(文本文件)或字节(二进制文件)size:指定要读取的字符数或字节数。如果未指定或为负数,则读取整个文件内容。- 返回读取的数据,类型为字符串(文本文件)或字节(二进制文件)
readline(size=-1):从文件中读取一行内容。size:指定要读取的字符数或字节数。如果未指定或为负数,则读取整行。- 返回读取的一行内容,类型为字符串(文本文件)或字节(二进制文件)。
readlines(hint=-1):从文件中读取所有行,并返回一个列表。hint:指定要读取的字符数或字节数。如果未指定或为负数,则读取所有行。- 返回一个列表,列表中的每个元素是文件的一行内容。
import os
# 打开文件
# os.getcwd() 获取绝对路径
path = os.getcwd()
filename = path + '/a.txt'
f = open(filename) # 绝对路径
# # 读取文件
context = f.read(5)
print(context,type(context))
f.close()
# 文件读取
file=open('a.txt','r')
# 读全部: 读出来的是一个list,每一行,一个元素
s=file.readlines()
print(s,type(s)) # ['Python\n', 'JavaPythonPythonPythonPython'] <class 'list'>
file.close()
file2=open('a.txt','r')
s2=file2.readline()# 读一行
print(s2,type(s2)) # Python <class 'str'>
file2.close()
# 追加模式
file=open('a.txt','a')
file.write('Python')
file.write('Python')
file.close()
# rb+wb 实现图片的复制
src_file=open('./PythonBase/1-类属性.png','rb')
target_file=open('1.png','wb')
target_file.write(src_file.read())
src_file.close()
target_file.close()
# + 以读写方式打开
'''
如果没有+,那么执行print(file.readlines())的时候会报错
UnsupportedOperation: not readable
这是因为 mode=a 只有写的权限
'''
file=open('a.txt','a+')
'''
需注意的是你若刚用‘a+’打开一个文件,一般不能直接读取,
因为此时光标已经是文件末尾,除非你把光标移动到初始位置或任意非末尾的位置。
'''
print(file.readlines()) # []
file.write('Python')
file.close()
光标操作
seek(offset,whence)函数:需要使用文件对象进行调用,无返回值。- offset 控制光标移动的位移量(字节)
- whence 模式
- 0 基于文件开头移动多少字节
- 1 基于光标当前所在位置移动多少字节
- 2 基于文件末尾移动多少字节
- 注意: 1和2只能在二进制模式下使用。 0无所谓
- tell函数:用来获取光标当前的位置(移动的字节数)
- 代码表示:文件名.tell( )
- 返回光标当前所在的字节数
file=open('a.txt','a+')
file.write('Python')
file.seek(0,0)# 把光标置于开头
print(file.readlines()) # ['Python\n', 'JavaPythonPython']
s=file.tell()
print(s,type(s)) # 23 <class 'int'>
file.close()
文件对象常用的方法
with语句:上下文管理器
语法:
with open(文件名,模式) as src_file: 操作src_file作用:不用手动关闭流
什么是上下文管理器:实现了
__enter__()方法和__exit__()方法open(文件名,模式):其为上下文表达式,结果为上下文管理器,上下文管理器同时创建一个运行时上下文,自动调用
__enter__()方法,并将返回值赋值给src_file离开运行时上下文,自动调用上下文管理器的特殊方法
__exit__()
# 上下文管理器
'''
MyContentMgr实现了特殊方法__enter__和__exit__,称该类对象遵循了上下文管理器协议
该类对象的实例对象称为上下文管理器
'''
class MyContentMgr(object):
def __enter__(self):
print('enter方法被调用执行了')
return self
def __exit__(self,exc_type,exc_val,exc_tb):
print('exit方法被执行了')
def show(self):
print('show方法被调用执行了')
def showError(self):
print('showError方法被调用执行了',1/0)
with MyContentMgr() as file: # 相当于file=MyContentMgr()
file.show()
print('走出with-----')
with MyContentMgr() as file: # 相当于file=MyContentMgr()
file.showError()
enter方法被调用执行了
show方法被调用执行了
exit方法被执行了
走出with-----
enter方法被调用执行了
exit方法被执行了
以下是错误日志:
---------------------------------------------------------------------------
ZeroDivisionError Traceback (most recent call last)
Cell In [93], line 20
18 print('走出with-----')
19 with MyContentMgr() as file: # 相当于file=MyContentMgr()
---> 20 file.showError()
Cell In [93], line 15, in MyContentMgr.showError(self)
14 def showError(self):
---> 15 print('showError方法被调用执行了',1/0)
ZeroDivisionError: division by zero
# rb+wb 实现图片的复制
with open('./PythonBase/1-类属性.png','rb') as src_file:
with open('2.png','wb') as target_file:
target_file.write(src_file.read())
csv文件的读写
import csv
# 打开文件,使用 'a+' 模式(追加模式,允许读取和写入)
'''newline : 参数用于控制文件的换行符处理行为
- None(默认值):
- 在写入文件时,Python 会将 \n 转换为当前操作系统的默认换行符:
- Windows:\n 转换为 \r\n。
- macOS 和 Linux:\n 保持不变。
- 在读取文件时,Python 会将文件中的换行符统一转换为 \n。
- ''(空字符串):
- 写入时:不进行换行符转换,直接写入 \n。
- 读取时:不进行换行符转换,保留文件中的原始换行符。
- 其他字符串(如 \n、\r\n):
- 写入时:将 \n 转换为指定的换行符。
- 读取时:将文件中的换行符统一转换为指定的换行符。
'''
'''
为什么配置newline=''?
- 在不同的操作系统中,换行符的表示方式不同:
- Windows 使用 \r\n(回车 + 换行)。
- Linux 和 macOS 使用 \n(换行)。
- Python 的 open 函数默认会对换行符进行转换:
- 在写入文件时,Python 会将 \n 转换为当前操作系统的换行符(例如,在 Windows 上转换为 \r\n)。
- 在读取文件时,Python 会将当前操作系统的换行符转换回 \n。
- CSV 模块的行为
- csv.writer 在写入数据时,会自动在每行的末尾添加换行符。
- 如果 open 函数也对换行符进行处理,会导致每行数据末尾多出一个换行符,从而在文件中产生额外的空行。
'''
'''
为什么 macOS 和 Linux 不会出现空行?
- csv.writer 写入的换行符是 \n。
- open 函数默认不会对换行符进行转换(因为 \n 已经是系统的标准换行符)。
- 因此,即使不指定 newline='',文件内容也不会出现额外的空行。
'''
'''
为什么建议始终使用 newline=''?
- 尽管在 macOS 和 Linux 上不指定 newline='' 也不会出现问题,
但为了代码的 跨平台兼容性,建议始终在写入 CSV 文件时指定 newline=''。这是因为:
- 如果你的代码在 Windows 系统上运行,不指定 newline='' 会导致额外的空行。
- 指定 newline='' 可以确保代码在所有操作系统上行为一致。
'''
with open('data.csv', mode='a+', encoding="utf-8",newline='') as file:
cf = csv.writer(file)
# 写入表头
cf.writerow(['姓名', '课程', '成绩'])
# 写入数据
listdata = [["jerry", 'python', '99'], ['tom', 'java', '88']]
cf.writerows(listdata)
# 将文件指针移动到文件开头,以便读取数据
file.seek(0)
# 读取文件内容
cr = csv.reader(file)
print(cr, type(cr)) # 打印迭代器对象
# 读取表头
head = next(cr)
print(head, type(head)) # 打印表头
# 读取并打印每一行数据
for row in cr:
print(row, type(row))
目录操作: os库
- os模块是Python内置的与操作系统功能和文件系统相关的模块,该模块中的语句的执行结果通常与操作系统有关,在不同的操作系统上运行,得到的结果可能不一样
- os模块与os.path模块用于对目录或文件进行操作
- os模块操作目录相关的函数
getcwd( ):返回当前的工作目录listdir(path):返回指定路径下的文件和目录信息mkdir(path,[,mode]):创建目录makedirs(path1/path2...[,mode]):创建多级目录rmdir(path):删除目录removedirs(path1/path2...):删除多级目录chdir(path):将path设置为当前工作目录
os.path模块操作目录相关的函数abspath(path):用于获取文件或目录的绝对路径exists(path):用于判断文件或目录是否存在,如果存在返回True,否则返回Falsejoin(path,name):将目录与目录或文件名拼接起来split(path):将文件路径和文件名分离splitext():分离文件名和拓展名basename(path):从一个目录中提取文件名dirname(path):从一个路径中提取文件路径,不包括文件名isdir(path):判断是否为路径
os.walk(path):获取path下所有文件和目录
import os
# os.system('应用名.exe')可以打开系统自动的软件
# mac的电脑还不知道怎么打开
#os.system('Stickies.app')
# 调用可执行文件:os.startfile(文件路径)mac电脑还不知到怎么弄
#os.startfile('/Applications/WeChat.app/Contents/MacOS/WeChat')
s=os.getcwd()
print(s)
print(os.listdir(s))
os.mkdir('newdir2')
os.makedirs('a/b/c')
os.rmdir('newdir2')
os.removedirs('a/b/c')
os.chdir('/Users/xieshaolin/workpalce/python/quant/newdir')
print(os.getcwd())
os.chdir('/Users/xieshaolin/workpalce/python/quant')
print(os.getcwd())
/Users/xieshaolin/workpalce/python/quant
['.DS_Store', 'python基础语法.ipynb', 'newdir', 'PythonBase', 'a.txt', 'numpy.ipynb', '.ipynb_checkpoints', 'python基础语法.md', '2.png', '1.png']
/Users/xieshaolin/workpalce/python/quant/newdir
/Users/xieshaolin/workpalce/python/quant
import os.path as op
print(op.abspath('a.txt'))
print(op.abspath('./PythonBase/1-类属性.png'))#可以用相对路径
print(op.exists('a.txt'),op.exists('b.txt'))
print(op.join('/Users','a.txt'))#不会校验,只是单纯拼接
print(op.split('/a/b/c'))# 不会区分,只是把最后一层分出来
print(op.splitext('/a/b/c.txt'))#不校验
print(op.basename('/a/b/c'))#不校验,只是提取最后一个
print(op.dirname('/a/b/c'))#不校验,提取前面的
# 会校验是不是真的目录
print(op.isdir('/a/b/c'),op.isdir('/a/b/c.txt'),
op.isdir('/Users/xieshaolin/workpalce/python/quant/a.txt'),
op.isdir('/Users/xieshaolin/workpalce/python/quant'))# ../a.txt是文件不是目录
/Users/xieshaolin/workpalce/python/quant/a.txt
/Users/xieshaolin/workpalce/python/quant/PythonBase/1-类属性.png
True False
/Users/a.txt
('/a/b', 'c')
('/a/b/c', '.txt')
c
/a/b
False False False True
# 列出指定目录下的所有文件
import os
path=os.getcwd()
pathlist=os.listdir(path)
for item in pathlist:
print(os.path.abspath(item))
/Users/xieshaolin/workpalce/python/quant/.DS_Store
/Users/xieshaolin/workpalce/python/quant/python基础语法.ipynb
/Users/xieshaolin/workpalce/python/quant/newdir
/Users/xieshaolin/workpalce/python/quant/PythonBase
/Users/xieshaolin/workpalce/python/quant/a.txt
/Users/xieshaolin/workpalce/python/quant/numpy.ipynb
/Users/xieshaolin/workpalce/python/quant/.ipynb_checkpoints
/Users/xieshaolin/workpalce/python/quant/python基础语法.md
/Users/xieshaolin/workpalce/python/quant/2.png
/Users/xieshaolin/workpalce/python/quant/1.png
import os
path=os.getcwd()
listFile=os.walk(path)
print(listFile,type(listFile))
print('------------------------------------')
for item in listFile:
print(item,type(item))# item 是一个元组
print('------------------------------------')
<generator object walk at 0x10b3ec9e0> <class 'generator'>
------------------------------------
('/Users/xieshaolin/workpalce/python/quant', ['newdir', 'PythonBase', '.ipynb_checkpoints'], ['.DS_Store', 'python基础语法.ipynb', 'a.txt', 'numpy.ipynb', 'python基础语法.md', '2.png', '1.png']) <class 'tuple'>
------------------------------------
('/Users/xieshaolin/workpalce/python/quant/newdir', [], []) <class 'tuple'>
------------------------------------
('/Users/xieshaolin/workpalce/python/quant/PythonBase', [], ['.DS_Store', '3-编码格式.jpeg', '2-动态绑定.png', '1-类属性.png']) <class 'tuple'>
------------------------------------
('/Users/xieshaolin/workpalce/python/quant/.ipynb_checkpoints', [], ['numpy-checkpoint.ipynb', 'python基础语法-checkpoint.ipynb']) <class 'tuple'>
------------------------------------
# 元组还可以这么遍历
ls=[(1,2,3),(4,5,6),(7,8,9)]
for a,b,c in ls:
print(a,b,c)
1 2 3
4 5 6
7 8 9
import os
path=os.getcwd()
listFile=os.walk(path)
'''
第一个:dirpath-当前路径
第二个:dirname-当前路径下的文件夹
第三个:filename-当前路径下的文件名
'''
for dirpath,dirname,filename in listFile:
for item in filename:
#print(os.path.abspath(item))这样不行,得出的结果是当前路径+文件名
print(os.path.join(dirpath,item))
print('--------------------------------------------------')
/Users/xieshaolin/workpalce/python/quant/.DS_Store
/Users/xieshaolin/workpalce/python/quant/python基础语法.ipynb
/Users/xieshaolin/workpalce/python/quant/a.txt
/Users/xieshaolin/workpalce/python/quant/numpy.ipynb
/Users/xieshaolin/workpalce/python/quant/python基础语法.md
/Users/xieshaolin/workpalce/python/quant/2.png
/Users/xieshaolin/workpalce/python/quant/1.png
--------------------------------------------------
--------------------------------------------------
/Users/xieshaolin/workpalce/python/quant/PythonBase/.DS_Store
/Users/xieshaolin/workpalce/python/quant/PythonBase/3-编码格式.jpeg
/Users/xieshaolin/workpalce/python/quant/PythonBase/2-动态绑定.png
/Users/xieshaolin/workpalce/python/quant/PythonBase/1-类属性.png
--------------------------------------------------
/Users/xieshaolin/workpalce/python/quant/.ipynb_checkpoints/numpy-checkpoint.ipynb
/Users/xieshaolin/workpalce/python/quant/.ipynb_checkpoints/python基础语法-checkpoint.ipynb
--------------------------------------------------

